
CV |
Bio |
Google Scholar |
I am an Assistant Professor at the MIT Media Lab and MIT EECS, where I direct the Multisensory Intelligence research group. In summer 2024, I was a visiting researcher in the AI, psychology, and neuroscience program at UC Berkeley's Simons Institute for the Theory of Computing. Previously, I received my Ph.D. from the Machine Learning Department at Carnegie Mellon University, advised by Louis-Philippe Morency and Ruslan Salakhutdinov. Prospective students: I am hiring at all levels (post-docs, PhDs, masters, undergrads, and visitors). If you want to join MIT as a graduate student, please apply through the programs in Media Arts & Sciences or EECS,
and mention my name in your application. |
|
arXiv |
code |
abstract |
bibtex
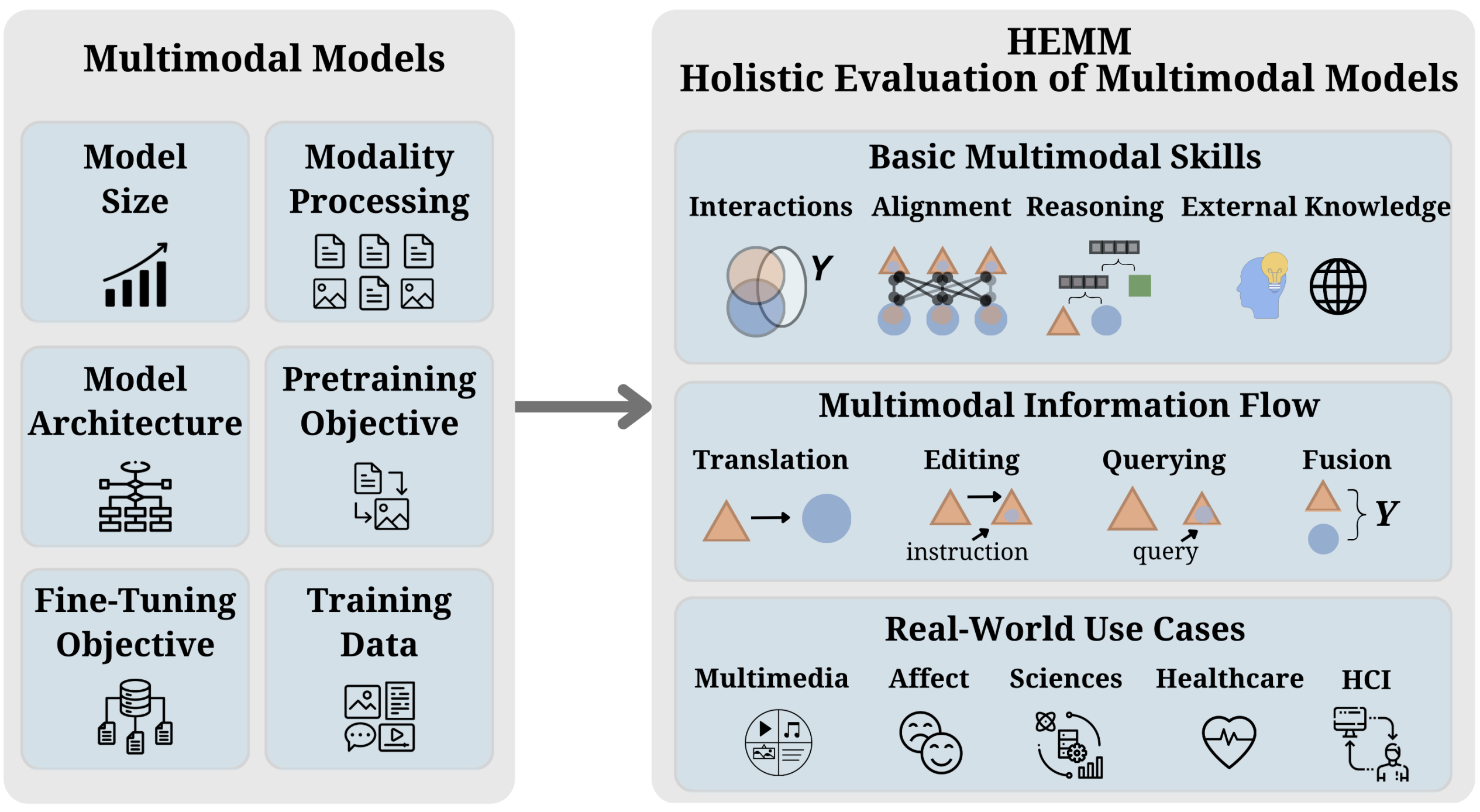
Multimodal foundation models that can holistically process text alongside images, video, audio, and other sensory modalities are increasingly used in a variety of real-world applications. However, it is challenging to characterize and study progress in multimodal foundation models, given the range of possible modeling decisions, tasks, and domains. In this paper, we introduce Holistic Evaluation of Multimodal Models (HEMM) to systematically evaluate the capabilities of multimodal foundation models across a set of 3 dimensions: basic skills, information flow, and real-world use cases. Basic multimodal skills are internal abilities required to solve problems, such as learning interactions across modalities, fine-grained alignment, multi-step reasoning, and the ability to handle external knowledge. Information flow studies how multimodal content changes during a task through querying, translation, editing, and fusion. Use cases span domain-specific challenges introduced in real-world multimedia, affective computing, natural sciences, healthcare, and human-computer interaction applications. Through comprehensive experiments across the 30 tasks in HEMM, we (1) identify key dataset dimensions (e.g., basic skills, information flows, and use cases) that pose challenges to today's models, and (2) distill performance trends regarding how different modeling dimensions (e.g., scale, pre-training data, multimodal alignment, pre-training, and instruction tuning objectives) influence performance. Our conclusions regarding challenging multimodal interactions, use cases, and tasks requiring reasoning and external knowledge, the benefits of data and model scale, and the impacts of instruction tuning yield actionable insights for future work in multimodal foundation models. |
|
arXiv |
code |
abstract |
bibtex
Analyzing human multimodal language is an emerging area of research in NLP. Intrinsically this language is multimodal (heterogeneous), sequential and asynchronous; it consists of the language (words), visual (expressions) and acoustic (paralinguistic) modalities all in the form of asynchronous coordinated sequences. From a resource perspective, there is a genuine need for large scale datasets that allow for in-depth studies of this form of language. In this paper we introduce CMU Multimodal Opinion Sentiment and Emotion Intensity (CMU-MOSEI), the largest dataset of sentiment analysis and emotion recognition to date. Using data from CMU-MOSEI and a novel multimodal fusion technique called the Dynamic Fusion Graph (DFG), we conduct experimentation to exploit how modalities interact with each other in human multimodal language. Unlike previously proposed fusion techniques, DFG is highly interpretable and achieves competative performance when compared to the previous state of the art. |
|
|
|
arXiv |
abstract |
bibtex
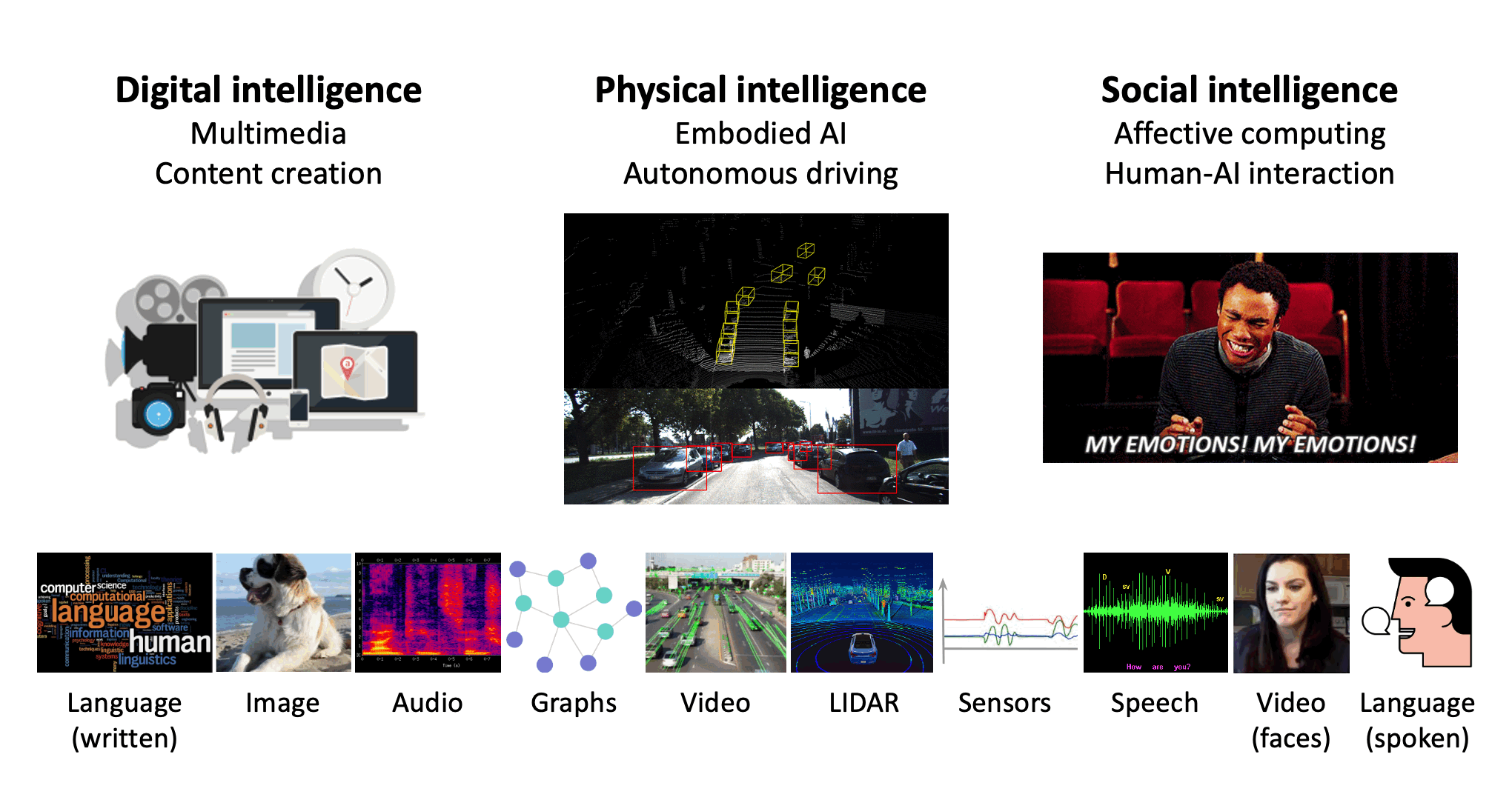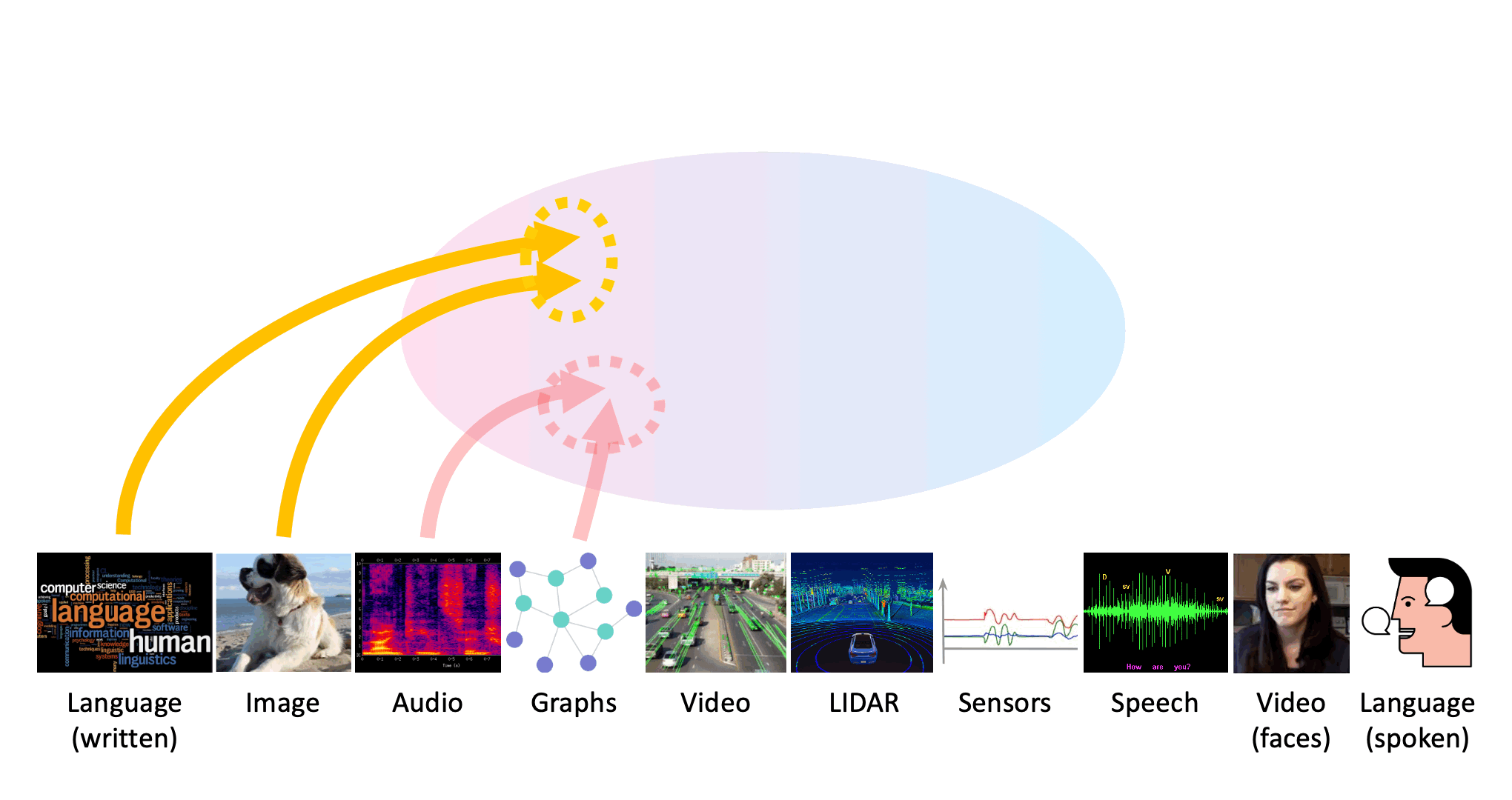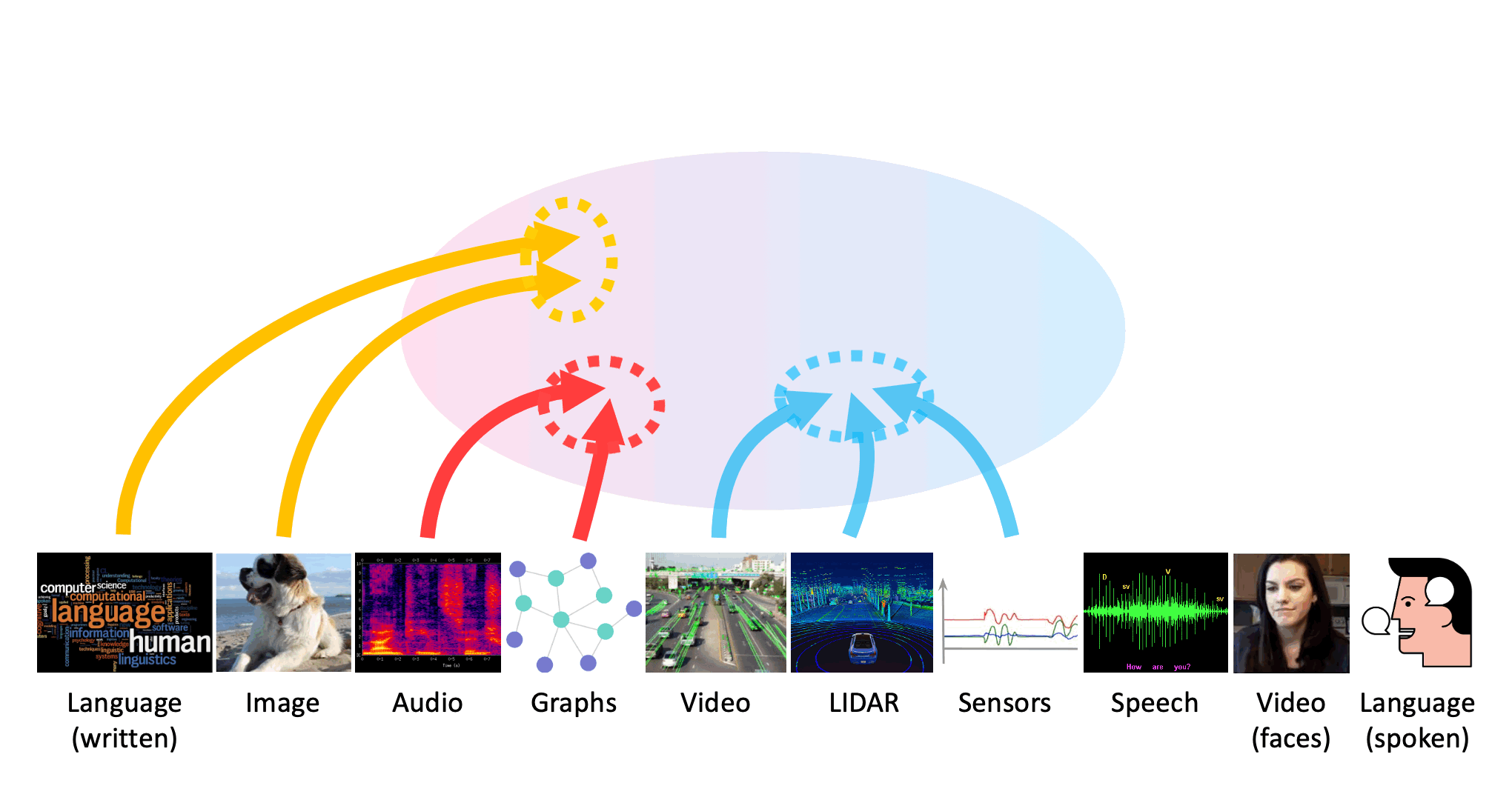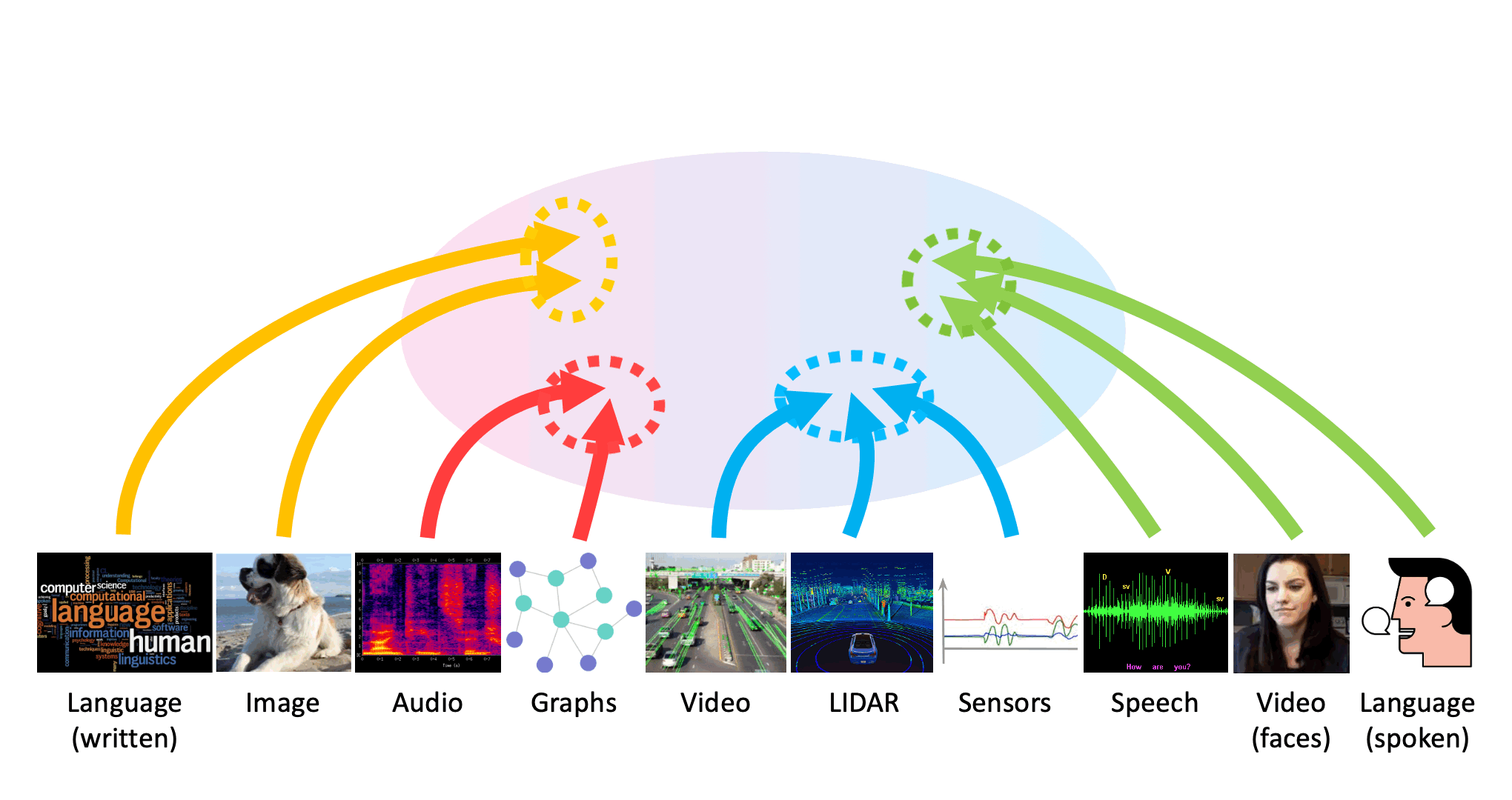
Multimodal machine learning is a vibrant multi-disciplinary research field that aims to design computer agents with intelligent capabilities such as understanding, reasoning, and learning through integrating multiple communicative modalities, including linguistic, acoustic, visual, tactile, and physiological messages. With the recent interest in video understanding, embodied autonomous agents, text-to-image generation, and multisensor fusion in application domains such as healthcare and robotics, multimodal machine learning has brought unique computational and theoretical challenges to the machine learning community given the heterogeneity of data sources and the interconnections often found between modalities. However, the breadth of progress in multimodal research has made it difficult to identify the common themes and open questions in the field. By synthesizing a broad range of application domains and theoretical frameworks from both historical and recent perspectives, this paper is designed to provide an overview of the computational and theoretical foundations of multimodal machine learning. We start by defining three key principles of modality heterogeneity, connections, and interactions that have driven subsequent innovations, and propose a taxonomy of six core technical challenges: representation, alignment, reasoning, generation, transference, and quantification covering historical and recent trends. Recent technical achievements will be presented through the lens of this taxonomy, allowing researchers to understand the similarities and differences across new approaches. We end by motivating several open problems for future research as identified by our taxonomy. |

|
arXiv |
website |
videos |
abstract |
bibtex
Multimodal machine learning is a vibrant multi-disciplinary research field that aims to design computer agents with intelligent capabilities such as understanding, reasoning, and learning through integrating multiple communicative modalities, including linguistic, acoustic, visual, tactile, and physiological messages. With the recent interest in video understanding, embodied autonomous agents, text-to-image generation, and multisensor fusion in application domains such as healthcare and robotics, multimodal machine learning has brought unique computational and theoretical challenges to the machine learning community given the heterogeneity of data sources and the interconnections often found between modalities. However, the breadth of progress in multimodal research has made it difficult to identify the common themes and open questions in the field. By synthesizing a broad range of application domains and theoretical frameworks from both historical and recent perspectives, this paper is designed to provide an overview of the computational and theoretical foundations of multimodal machine learning. We start by defining three key principles of modality heterogeneity, connections, and interactions that have driven subsequent innovations, and propose a taxonomy of six core technical challenges: representation, alignment, reasoning, generation, transference, and quantification covering historical and recent trends. Recent technical achievements will be presented through the lens of this taxonomy, allowing researchers to understand the similarities and differences across new approaches. We end by motivating several open problems for future research as identified by our taxonomy. |
|
arXiv |
code |
abstract |
bibtex
Analyzing human multimodal language is an emerging area of research in NLP. Intrinsically this language is multimodal (heterogeneous), sequential and asynchronous; it consists of the language (words), visual (expressions) and acoustic (paralinguistic) modalities all in the form of asynchronous coordinated sequences. From a resource perspective, there is a genuine need for large scale datasets that allow for in-depth studies of this form of language. In this paper we introduce CMU Multimodal Opinion Sentiment and Emotion Intensity (CMU-MOSEI), the largest dataset of sentiment analysis and emotion recognition to date. Using data from CMU-MOSEI and a novel multimodal fusion technique called the Dynamic Fusion Graph (DFG), we conduct experimentation to exploit how modalities interact with each other in human multimodal language. Unlike previously proposed fusion techniques, DFG is highly interpretable and achieves competative performance when compared to the previous state of the art. |
|
arXiv |
code |
abstract |
bibtex
Analyzing human multimodal language is an emerging area of research in NLP. Intrinsically this language is multimodal (heterogeneous), sequential and asynchronous; it consists of the language (words), visual (expressions) and acoustic (paralinguistic) modalities all in the form of asynchronous coordinated sequences. From a resource perspective, there is a genuine need for large scale datasets that allow for in-depth studies of this form of language. In this paper we introduce CMU Multimodal Opinion Sentiment and Emotion Intensity (CMU-MOSEI), the largest dataset of sentiment analysis and emotion recognition to date. Using data from CMU-MOSEI and a novel multimodal fusion technique called the Dynamic Fusion Graph (DFG), we conduct experimentation to exploit how modalities interact with each other in human multimodal language. Unlike previously proposed fusion techniques, DFG is highly interpretable and achieves competative performance when compared to the previous state of the art. |
|
arXiv |
code |
abstract |
bibtex
Analyzing human multimodal language is an emerging area of research in NLP. Intrinsically this language is multimodal (heterogeneous), sequential and asynchronous; it consists of the language (words), visual (expressions) and acoustic (paralinguistic) modalities all in the form of asynchronous coordinated sequences. From a resource perspective, there is a genuine need for large scale datasets that allow for in-depth studies of this form of language. In this paper we introduce CMU Multimodal Opinion Sentiment and Emotion Intensity (CMU-MOSEI), the largest dataset of sentiment analysis and emotion recognition to date. Using data from CMU-MOSEI and a novel multimodal fusion technique called the Dynamic Fusion Graph (DFG), we conduct experimentation to exploit how modalities interact with each other in human multimodal language. Unlike previously proposed fusion techniques, DFG is highly interpretable and achieves competative performance when compared to the previous state of the art. |
|
arXiv |
code |
abstract |
bibtex
Analyzing human multimodal language is an emerging area of research in NLP. Intrinsically this language is multimodal (heterogeneous), sequential and asynchronous; it consists of the language (words), visual (expressions) and acoustic (paralinguistic) modalities all in the form of asynchronous coordinated sequences. From a resource perspective, there is a genuine need for large scale datasets that allow for in-depth studies of this form of language. In this paper we introduce CMU Multimodal Opinion Sentiment and Emotion Intensity (CMU-MOSEI), the largest dataset of sentiment analysis and emotion recognition to date. Using data from CMU-MOSEI and a novel multimodal fusion technique called the Dynamic Fusion Graph (DFG), we conduct experimentation to exploit how modalities interact with each other in human multimodal language. Unlike previously proposed fusion techniques, DFG is highly interpretable and achieves competative performance when compared to the previous state of the art. |
|
arXiv |
code |
abstract |
bibtex
Analyzing human multimodal language is an emerging area of research in NLP. Intrinsically this language is multimodal (heterogeneous), sequential and asynchronous; it consists of the language (words), visual (expressions) and acoustic (paralinguistic) modalities all in the form of asynchronous coordinated sequences. From a resource perspective, there is a genuine need for large scale datasets that allow for in-depth studies of this form of language. In this paper we introduce CMU Multimodal Opinion Sentiment and Emotion Intensity (CMU-MOSEI), the largest dataset of sentiment analysis and emotion recognition to date. Using data from CMU-MOSEI and a novel multimodal fusion technique called the Dynamic Fusion Graph (DFG), we conduct experimentation to exploit how modalities interact with each other in human multimodal language. Unlike previously proposed fusion techniques, DFG is highly interpretable and achieves competative performance when compared to the previous state of the art. |
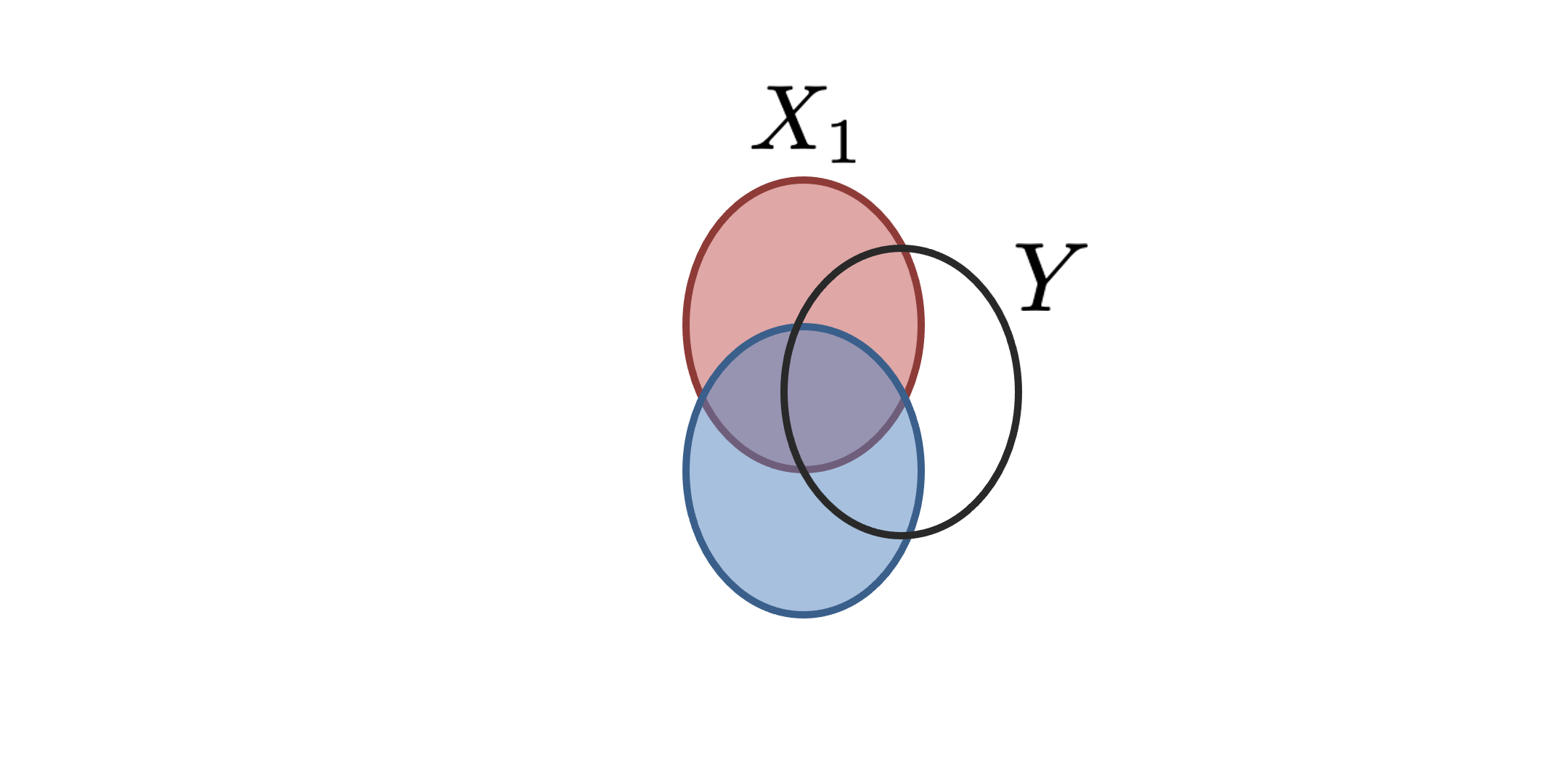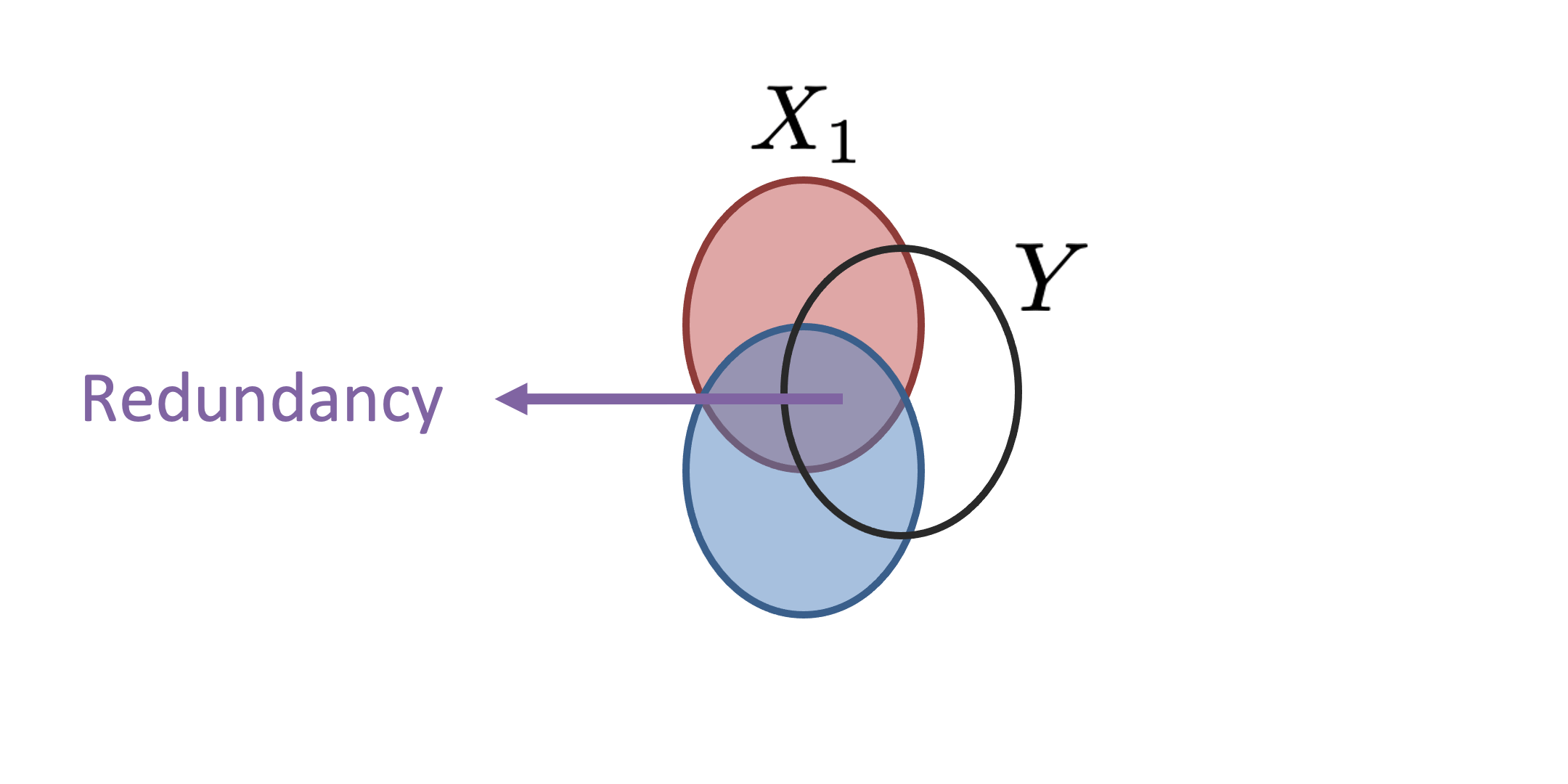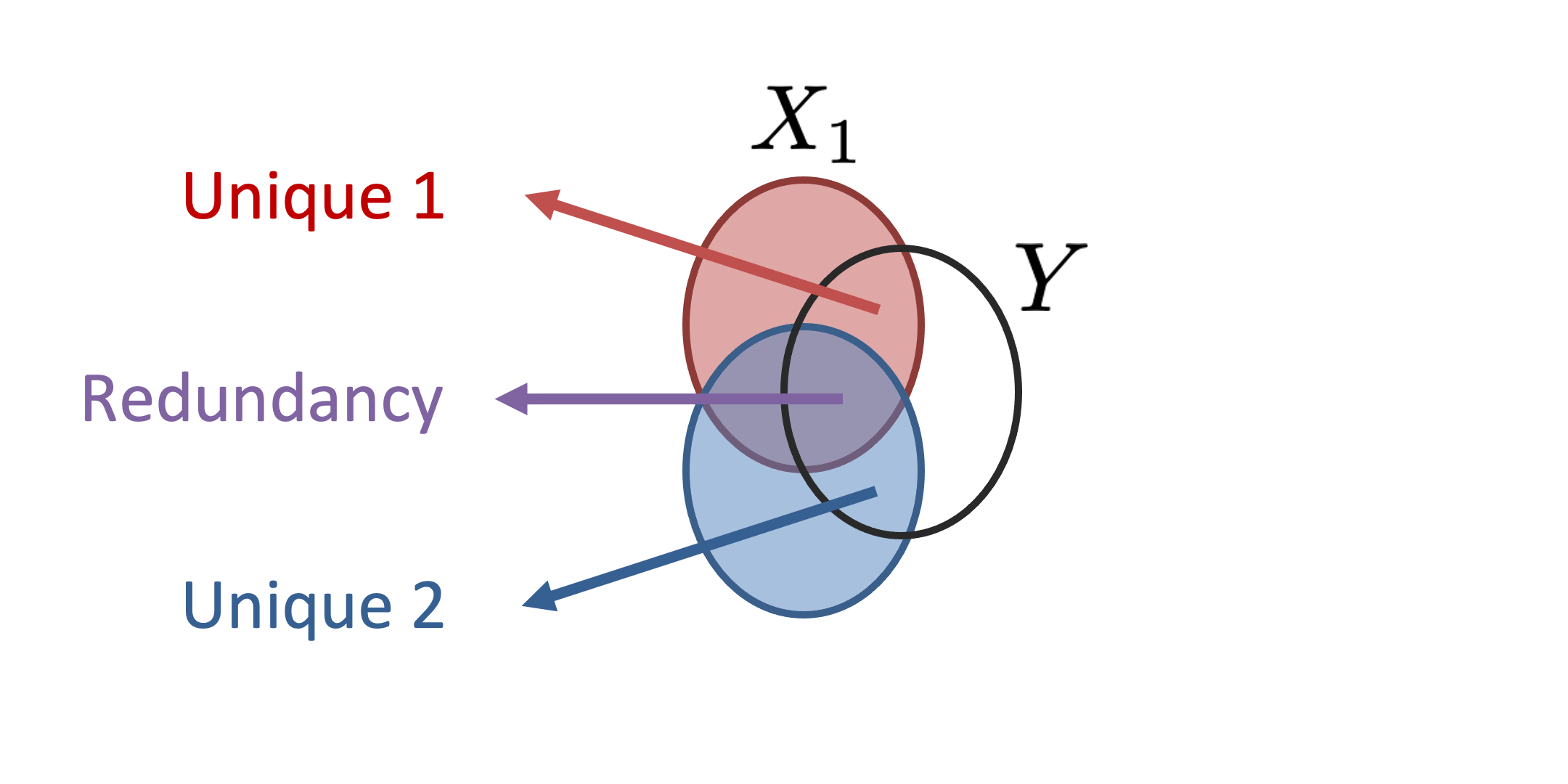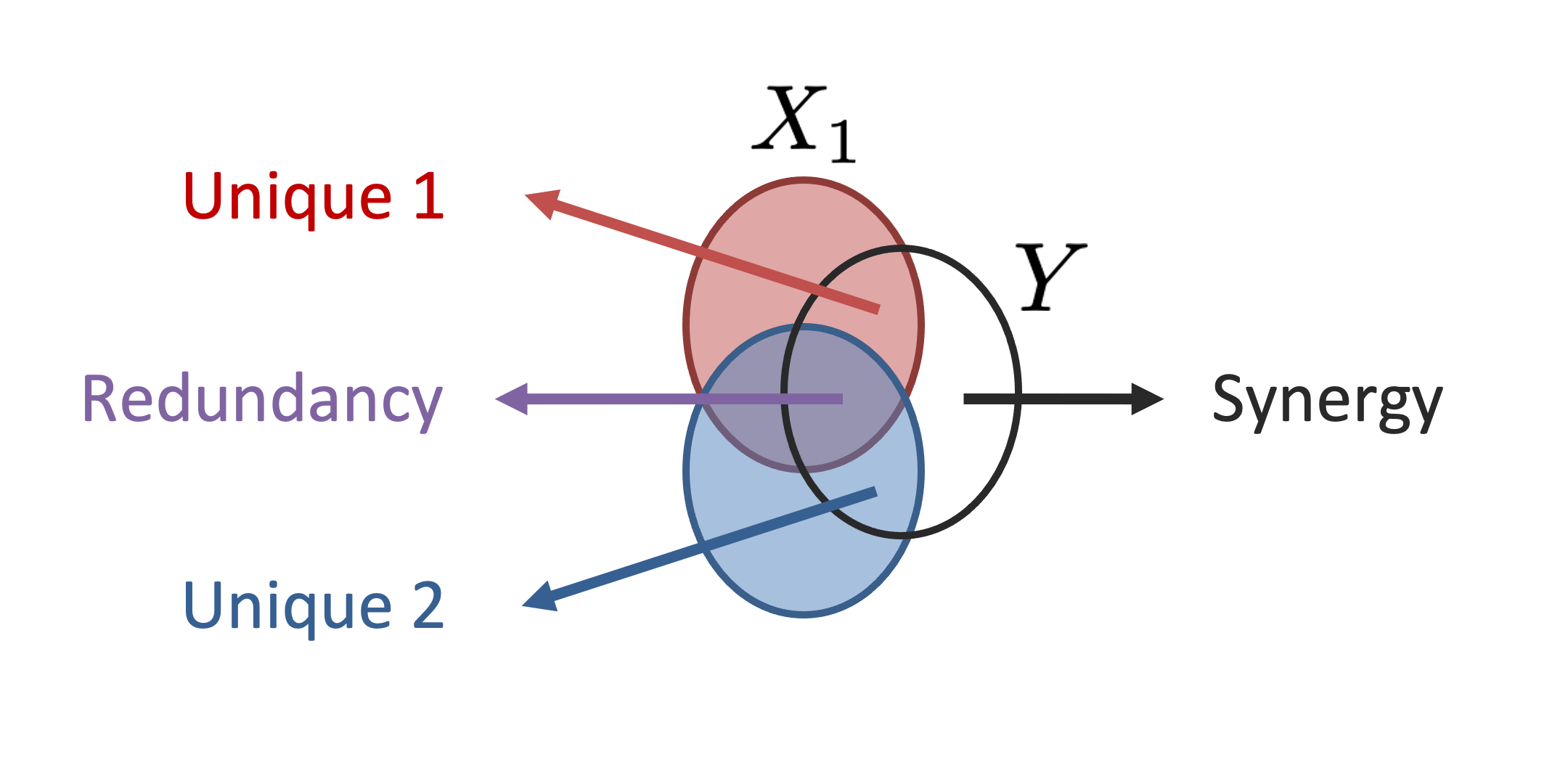
|
arXiv |
code |
abstract |
bibtex
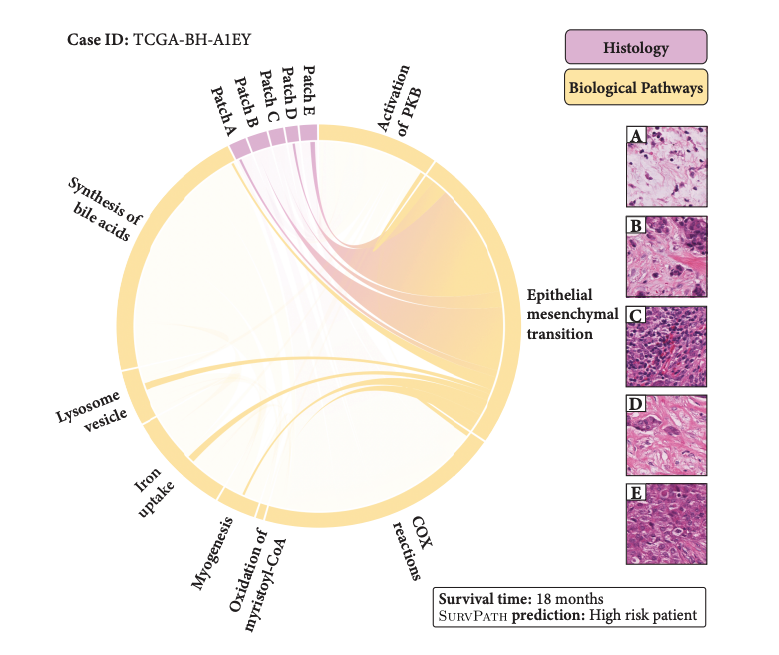
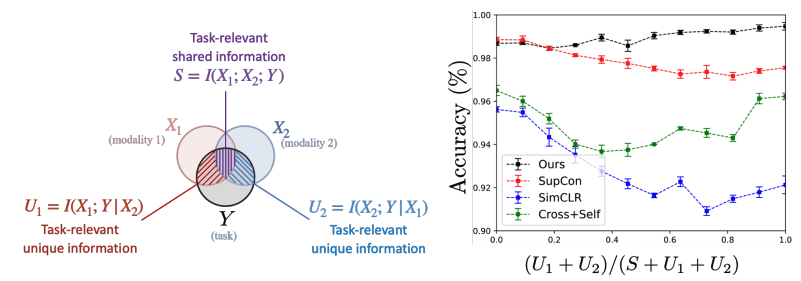
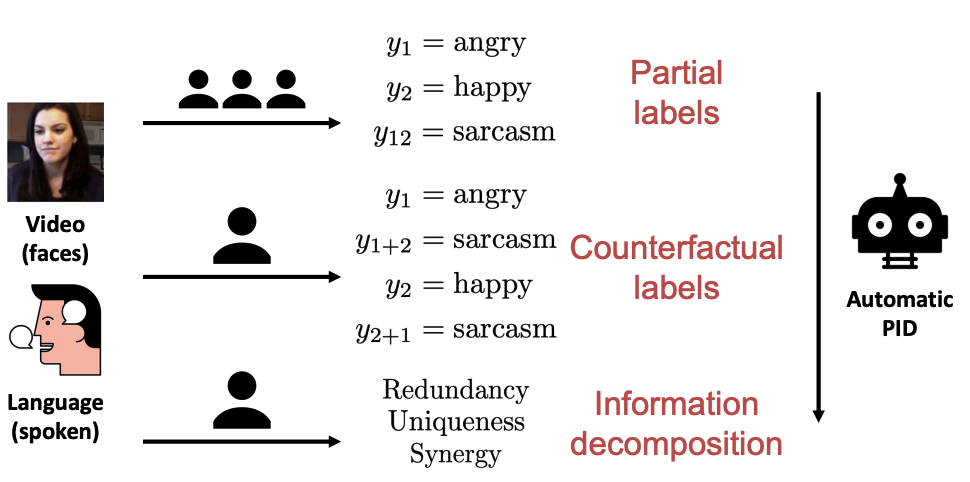
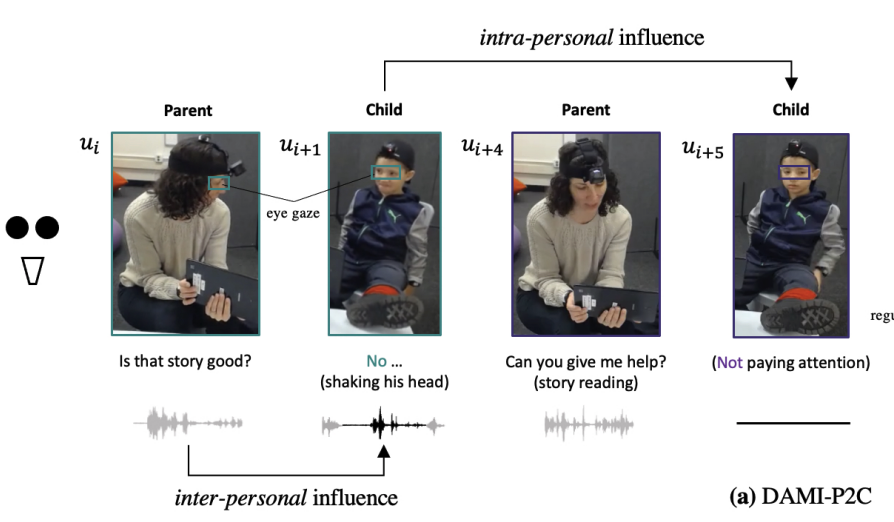
The recent explosion of interest in multimodal applications has resulted in a wide selection of datasets and methods for representing and integrating information from different modalities. Despite these empirical advances, there remain fundamental research questions: How can we quantify the interactions that are necessary to solve a multimodal task? Subsequently, what are the most suitable multimodal models to capture these interactions? To answer these questions, we propose an information-theoretic approach to quantify the degree of redundancy, uniqueness, and synergy relating input modalities with an output task. We term these three measures as the PID statistics of a multimodal distribution (or PID for short), and introduce two new estimators for these PID statistics that scale to high-dimensional distributions. To validate PID estimation, we conduct extensive experiments on both synthetic datasets where the PID is known and on large-scale multimodal benchmarks where PID estimations are compared with human annotations. Finally, we demonstrate their usefulness in (1) quantifying interactions within multimodal datasets, (2) quantifying interactions captured by multimodal models, (3) principled approaches for model selection, and (4) three real-world case studies engaging with domain experts in pathology, mood prediction, and robotic perception where our framework helps to recommend strong multimodal models for each application. |
|
arXiv |
code |
abstract |
bibtex
Analyzing human multimodal language is an emerging area of research in NLP. Intrinsically this language is multimodal (heterogeneous), sequential and asynchronous; it consists of the language (words), visual (expressions) and acoustic (paralinguistic) modalities all in the form of asynchronous coordinated sequences. From a resource perspective, there is a genuine need for large scale datasets that allow for in-depth studies of this form of language. In this paper we introduce CMU Multimodal Opinion Sentiment and Emotion Intensity (CMU-MOSEI), the largest dataset of sentiment analysis and emotion recognition to date. Using data from CMU-MOSEI and a novel multimodal fusion technique called the Dynamic Fusion Graph (DFG), we conduct experimentation to exploit how modalities interact with each other in human multimodal language. Unlike previously proposed fusion techniques, DFG is highly interpretable and achieves competative performance when compared to the previous state of the art. |
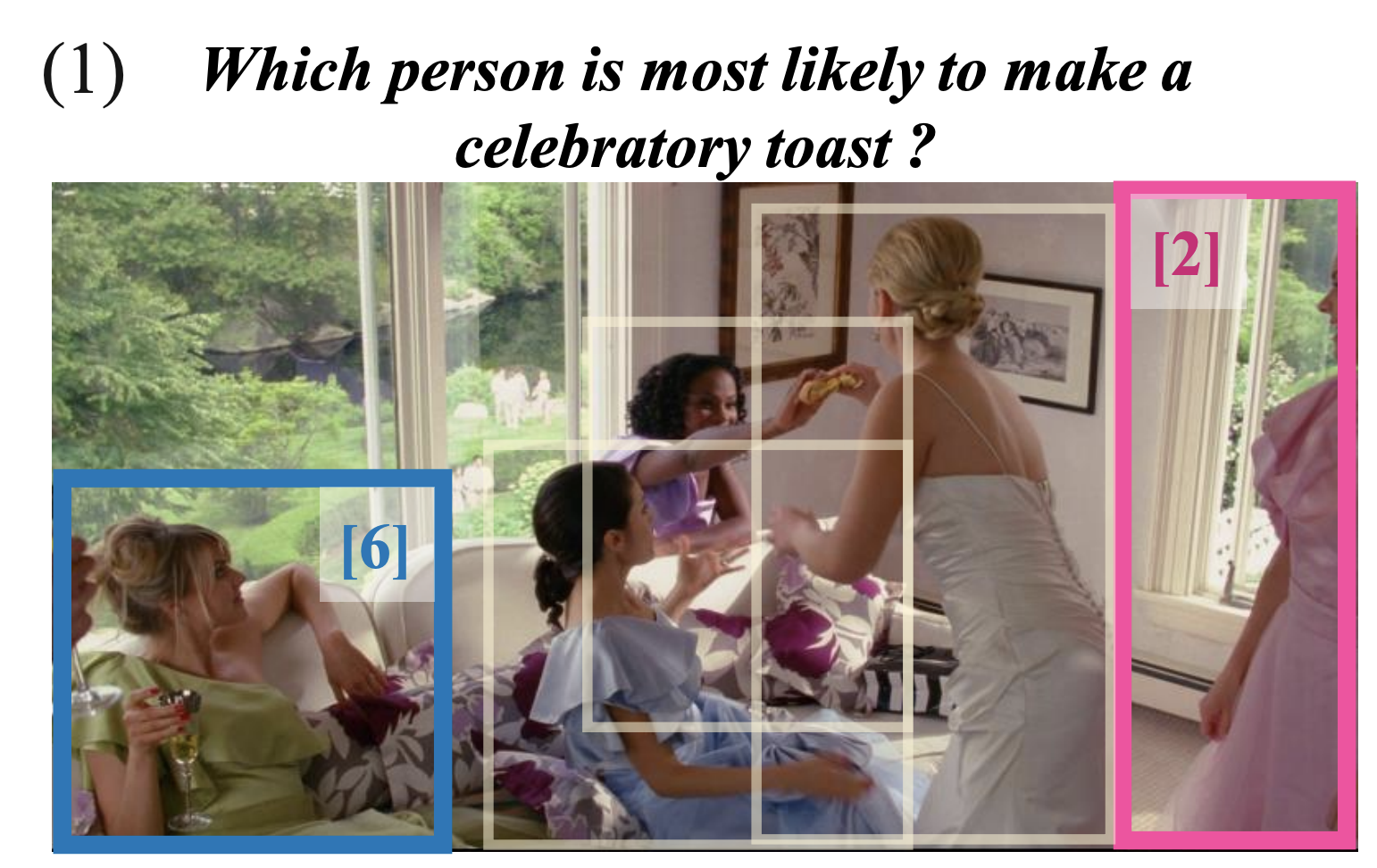
|
arXiv |
code |
abstract |
bibtex
Analyzing human multimodal language is an emerging area of research in NLP. Intrinsically this language is multimodal (heterogeneous), sequential and asynchronous; it consists of the language (words), visual (expressions) and acoustic (paralinguistic) modalities all in the form of asynchronous coordinated sequences. From a resource perspective, there is a genuine need for large scale datasets that allow for in-depth studies of this form of language. In this paper we introduce CMU Multimodal Opinion Sentiment and Emotion Intensity (CMU-MOSEI), the largest dataset of sentiment analysis and emotion recognition to date. Using data from CMU-MOSEI and a novel multimodal fusion technique called the Dynamic Fusion Graph (DFG), we conduct experimentation to exploit how modalities interact with each other in human multimodal language. Unlike previously proposed fusion techniques, DFG is highly interpretable and achieves competative performance when compared to the previous state of the art. |

|
arXiv |
code |
abstract |
bibtex
Analyzing human multimodal language is an emerging area of research in NLP. Intrinsically this language is multimodal (heterogeneous), sequential and asynchronous; it consists of the language (words), visual (expressions) and acoustic (paralinguistic) modalities all in the form of asynchronous coordinated sequences. From a resource perspective, there is a genuine need for large scale datasets that allow for in-depth studies of this form of language. In this paper we introduce CMU Multimodal Opinion Sentiment and Emotion Intensity (CMU-MOSEI), the largest dataset of sentiment analysis and emotion recognition to date. Using data from CMU-MOSEI and a novel multimodal fusion technique called the Dynamic Fusion Graph (DFG), we conduct experimentation to exploit how modalities interact with each other in human multimodal language. Unlike previously proposed fusion techniques, DFG is highly interpretable and achieves competative performance when compared to the previous state of the art. |

|
arXiv |
code |
abstract |
bibtex
Analyzing human multimodal language is an emerging area of research in NLP. Intrinsically this language is multimodal (heterogeneous), sequential and asynchronous; it consists of the language (words), visual (expressions) and acoustic (paralinguistic) modalities all in the form of asynchronous coordinated sequences. From a resource perspective, there is a genuine need for large scale datasets that allow for in-depth studies of this form of language. In this paper we introduce CMU Multimodal Opinion Sentiment and Emotion Intensity (CMU-MOSEI), the largest dataset of sentiment analysis and emotion recognition to date. Using data from CMU-MOSEI and a novel multimodal fusion technique called the Dynamic Fusion Graph (DFG), we conduct experimentation to exploit how modalities interact with each other in human multimodal language. Unlike previously proposed fusion techniques, DFG is highly interpretable and achieves competative performance when compared to the previous state of the art. |
|
arXiv |
code |
abstract |
bibtex
Analyzing human multimodal language is an emerging area of research in NLP. Intrinsically this language is multimodal (heterogeneous), sequential and asynchronous; it consists of the language (words), visual (expressions) and acoustic (paralinguistic) modalities all in the form of asynchronous coordinated sequences. From a resource perspective, there is a genuine need for large scale datasets that allow for in-depth studies of this form of language. In this paper we introduce CMU Multimodal Opinion Sentiment and Emotion Intensity (CMU-MOSEI), the largest dataset of sentiment analysis and emotion recognition to date. Using data from CMU-MOSEI and a novel multimodal fusion technique called the Dynamic Fusion Graph (DFG), we conduct experimentation to exploit how modalities interact with each other in human multimodal language. Unlike previously proposed fusion techniques, DFG is highly interpretable and achieves competative performance when compared to the previous state of the art. |
|
arXiv |
abstract |
bibtex
Analyzing human multimodal language is an emerging area of research in NLP. Intrinsically this language is multimodal (heterogeneous), sequential and asynchronous; it consists of the language (words), visual (expressions) and acoustic (paralinguistic) modalities all in the form of asynchronous coordinated sequences. From a resource perspective, there is a genuine need for large scale datasets that allow for in-depth studies of this form of language. In this paper we introduce CMU Multimodal Opinion Sentiment and Emotion Intensity (CMU-MOSEI), the largest dataset of sentiment analysis and emotion recognition to date. Using data from CMU-MOSEI and a novel multimodal fusion technique called the Dynamic Fusion Graph (DFG), we conduct experimentation to exploit how modalities interact with each other in human multimodal language. Unlike previously proposed fusion techniques, DFG is highly interpretable and achieves competative performance when compared to the previous state of the art. |

|
arXiv |
code |
abstract |
bibtex
Analyzing human multimodal language is an emerging area of research in NLP. Intrinsically this language is multimodal (heterogeneous), sequential and asynchronous; it consists of the language (words), visual (expressions) and acoustic (paralinguistic) modalities all in the form of asynchronous coordinated sequences. From a resource perspective, there is a genuine need for large scale datasets that allow for in-depth studies of this form of language. In this paper we introduce CMU Multimodal Opinion Sentiment and Emotion Intensity (CMU-MOSEI), the largest dataset of sentiment analysis and emotion recognition to date. Using data from CMU-MOSEI and a novel multimodal fusion technique called the Dynamic Fusion Graph (DFG), we conduct experimentation to exploit how modalities interact with each other in human multimodal language. Unlike previously proposed fusion techniques, DFG is highly interpretable and achieves competative performance when compared to the previous state of the art. |
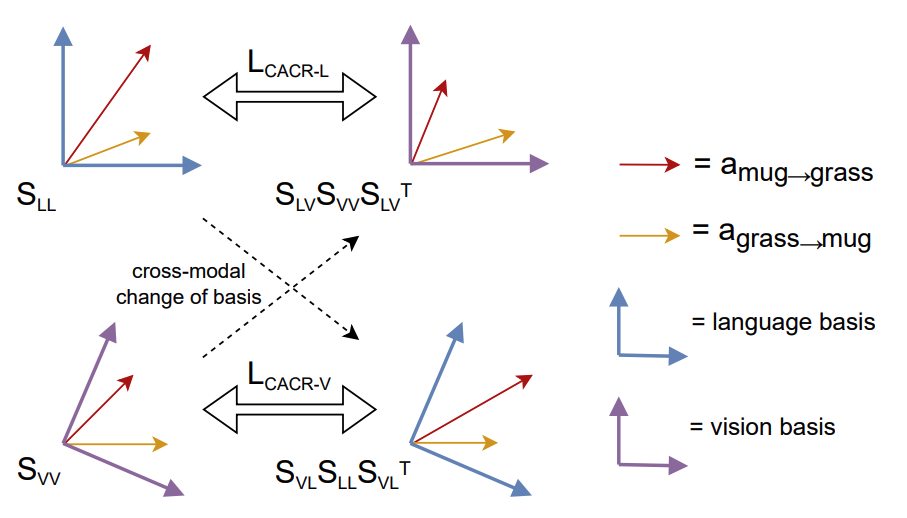
|
arXiv |
code |
abstract |
bibtex
Analyzing human multimodal language is an emerging area of research in NLP. Intrinsically this language is multimodal (heterogeneous), sequential and asynchronous; it consists of the language (words), visual (expressions) and acoustic (paralinguistic) modalities all in the form of asynchronous coordinated sequences. From a resource perspective, there is a genuine need for large scale datasets that allow for in-depth studies of this form of language. In this paper we introduce CMU Multimodal Opinion Sentiment and Emotion Intensity (CMU-MOSEI), the largest dataset of sentiment analysis and emotion recognition to date. Using data from CMU-MOSEI and a novel multimodal fusion technique called the Dynamic Fusion Graph (DFG), we conduct experimentation to exploit how modalities interact with each other in human multimodal language. Unlike previously proposed fusion techniques, DFG is highly interpretable and achieves competative performance when compared to the previous state of the art. |
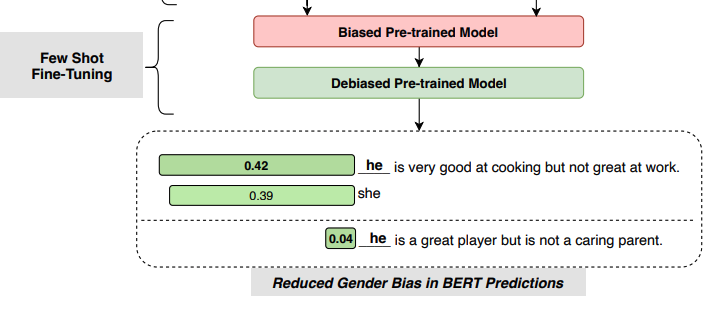
|
arXiv |
code |
abstract |
bibtex
Analyzing human multimodal language is an emerging area of research in NLP. Intrinsically this language is multimodal (heterogeneous), sequential and asynchronous; it consists of the language (words), visual (expressions) and acoustic (paralinguistic) modalities all in the form of asynchronous coordinated sequences. From a resource perspective, there is a genuine need for large scale datasets that allow for in-depth studies of this form of language. In this paper we introduce CMU Multimodal Opinion Sentiment and Emotion Intensity (CMU-MOSEI), the largest dataset of sentiment analysis and emotion recognition to date. Using data from CMU-MOSEI and a novel multimodal fusion technique called the Dynamic Fusion Graph (DFG), we conduct experimentation to exploit how modalities interact with each other in human multimodal language. Unlike previously proposed fusion techniques, DFG is highly interpretable and achieves competative performance when compared to the previous state of the art. |
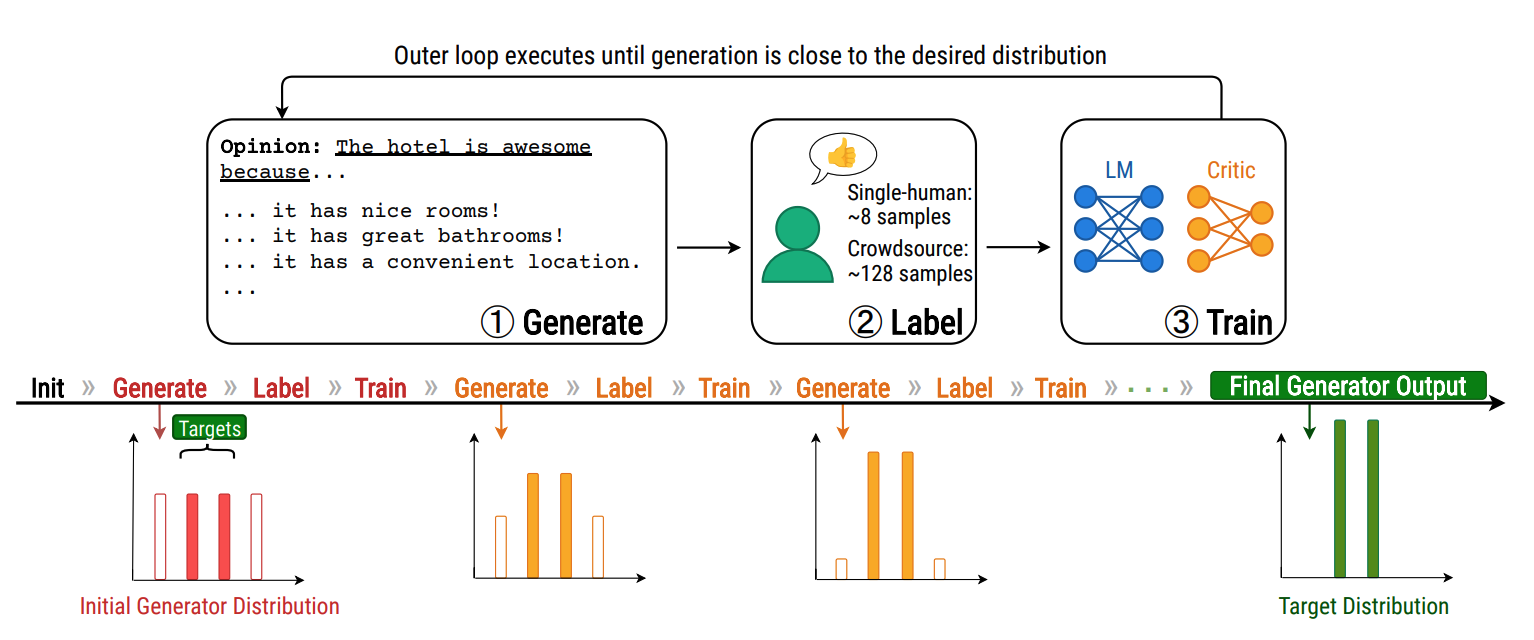
|
arXiv |
code |
abstract |
bibtex
Analyzing human multimodal language is an emerging area of research in NLP. Intrinsically this language is multimodal (heterogeneous), sequential and asynchronous; it consists of the language (words), visual (expressions) and acoustic (paralinguistic) modalities all in the form of asynchronous coordinated sequences. From a resource perspective, there is a genuine need for large scale datasets that allow for in-depth studies of this form of language. In this paper we introduce CMU Multimodal Opinion Sentiment and Emotion Intensity (CMU-MOSEI), the largest dataset of sentiment analysis and emotion recognition to date. Using data from CMU-MOSEI and a novel multimodal fusion technique called the Dynamic Fusion Graph (DFG), we conduct experimentation to exploit how modalities interact with each other in human multimodal language. Unlike previously proposed fusion techniques, DFG is highly interpretable and achieves competative performance when compared to the previous state of the art. |
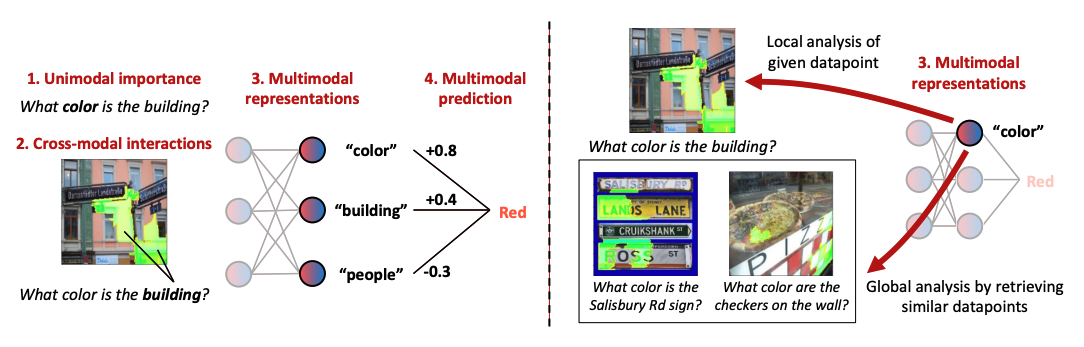
|
arXiv |
code |
abstract |
bibtex
Analyzing human multimodal language is an emerging area of research in NLP. Intrinsically this language is multimodal (heterogeneous), sequential and asynchronous; it consists of the language (words), visual (expressions) and acoustic (paralinguistic) modalities all in the form of asynchronous coordinated sequences. From a resource perspective, there is a genuine need for large scale datasets that allow for in-depth studies of this form of language. In this paper we introduce CMU Multimodal Opinion Sentiment and Emotion Intensity (CMU-MOSEI), the largest dataset of sentiment analysis and emotion recognition to date. Using data from CMU-MOSEI and a novel multimodal fusion technique called the Dynamic Fusion Graph (DFG), we conduct experimentation to exploit how modalities interact with each other in human multimodal language. Unlike previously proposed fusion techniques, DFG is highly interpretable and achieves competative performance when compared to the previous state of the art. |
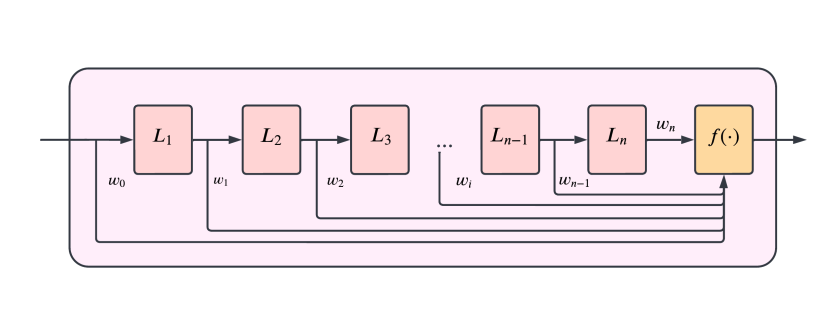
|
arXiv |
abstract |
bibtex
Analyzing human multimodal language is an emerging area of research in NLP. Intrinsically this language is multimodal (heterogeneous), sequential and asynchronous; it consists of the language (words), visual (expressions) and acoustic (paralinguistic) modalities all in the form of asynchronous coordinated sequences. From a resource perspective, there is a genuine need for large scale datasets that allow for in-depth studies of this form of language. In this paper we introduce CMU Multimodal Opinion Sentiment and Emotion Intensity (CMU-MOSEI), the largest dataset of sentiment analysis and emotion recognition to date. Using data from CMU-MOSEI and a novel multimodal fusion technique called the Dynamic Fusion Graph (DFG), we conduct experimentation to exploit how modalities interact with each other in human multimodal language. Unlike previously proposed fusion techniques, DFG is highly interpretable and achieves competative performance when compared to the previous state of the art. |
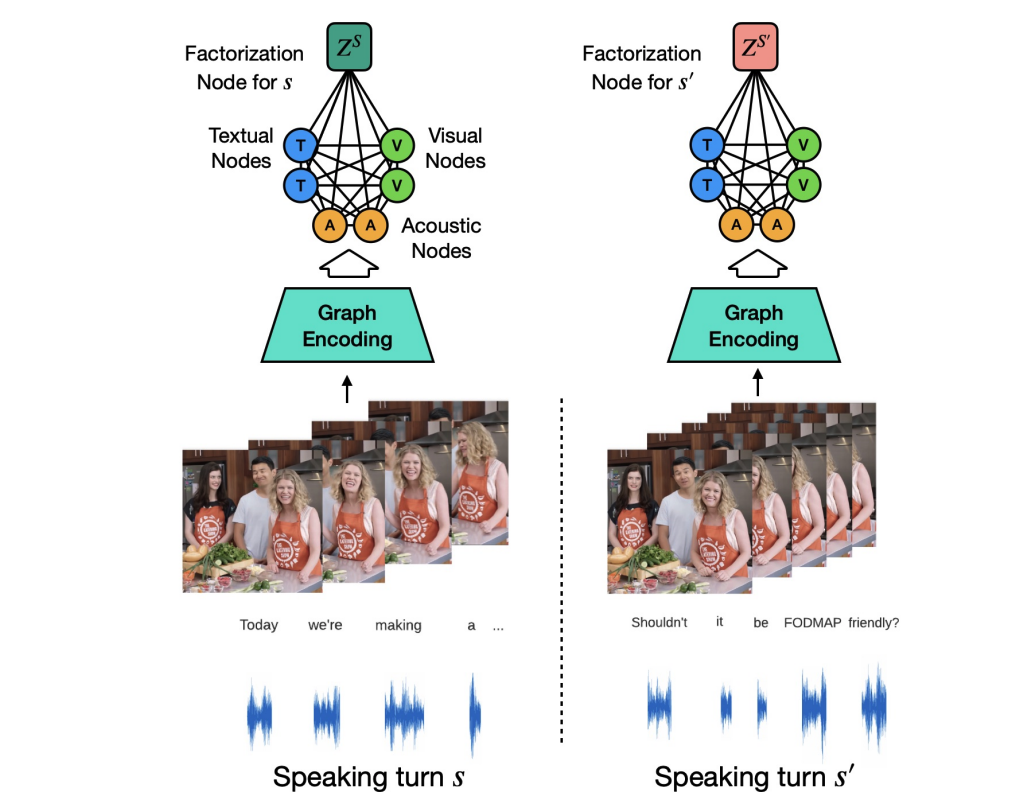
|
arXiv |
code |
abstract |
bibtex
Analyzing human multimodal language is an emerging area of research in NLP. Intrinsically this language is multimodal (heterogeneous), sequential and asynchronous; it consists of the language (words), visual (expressions) and acoustic (paralinguistic) modalities all in the form of asynchronous coordinated sequences. From a resource perspective, there is a genuine need for large scale datasets that allow for in-depth studies of this form of language. In this paper we introduce CMU Multimodal Opinion Sentiment and Emotion Intensity (CMU-MOSEI), the largest dataset of sentiment analysis and emotion recognition to date. Using data from CMU-MOSEI and a novel multimodal fusion technique called the Dynamic Fusion Graph (DFG), we conduct experimentation to exploit how modalities interact with each other in human multimodal language. Unlike previously proposed fusion techniques, DFG is highly interpretable and achieves competative performance when compared to the previous state of the art. |

|
arXiv |
code |
abstract |
bibtex
Analyzing human multimodal language is an emerging area of research in NLP. Intrinsically this language is multimodal (heterogeneous), sequential and asynchronous; it consists of the language (words), visual (expressions) and acoustic (paralinguistic) modalities all in the form of asynchronous coordinated sequences. From a resource perspective, there is a genuine need for large scale datasets that allow for in-depth studies of this form of language. In this paper we introduce CMU Multimodal Opinion Sentiment and Emotion Intensity (CMU-MOSEI), the largest dataset of sentiment analysis and emotion recognition to date. Using data from CMU-MOSEI and a novel multimodal fusion technique called the Dynamic Fusion Graph (DFG), we conduct experimentation to exploit how modalities interact with each other in human multimodal language. Unlike previously proposed fusion techniques, DFG is highly interpretable and achieves competative performance when compared to the previous state of the art. |

|
arXiv |
code |
abstract |
bibtex
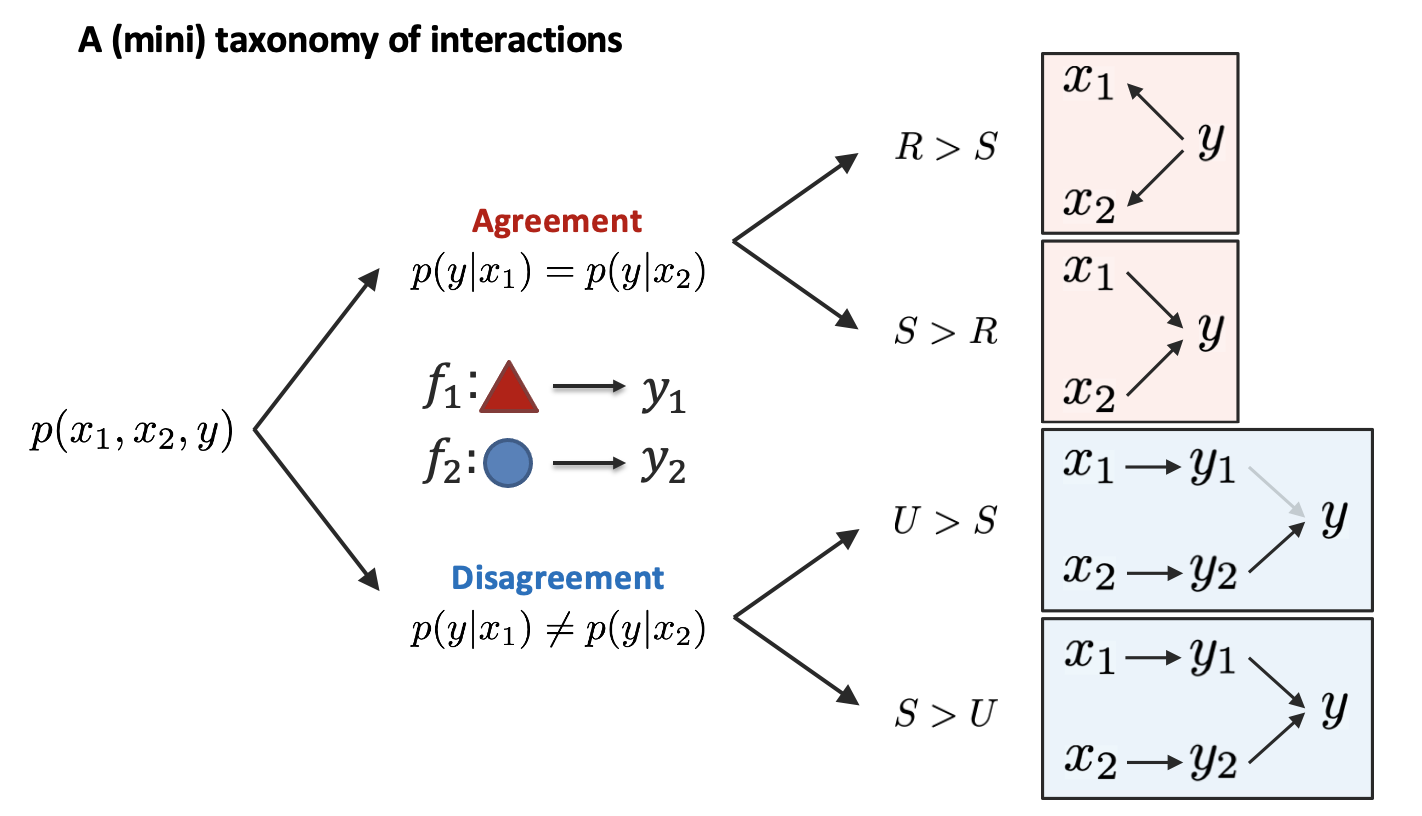
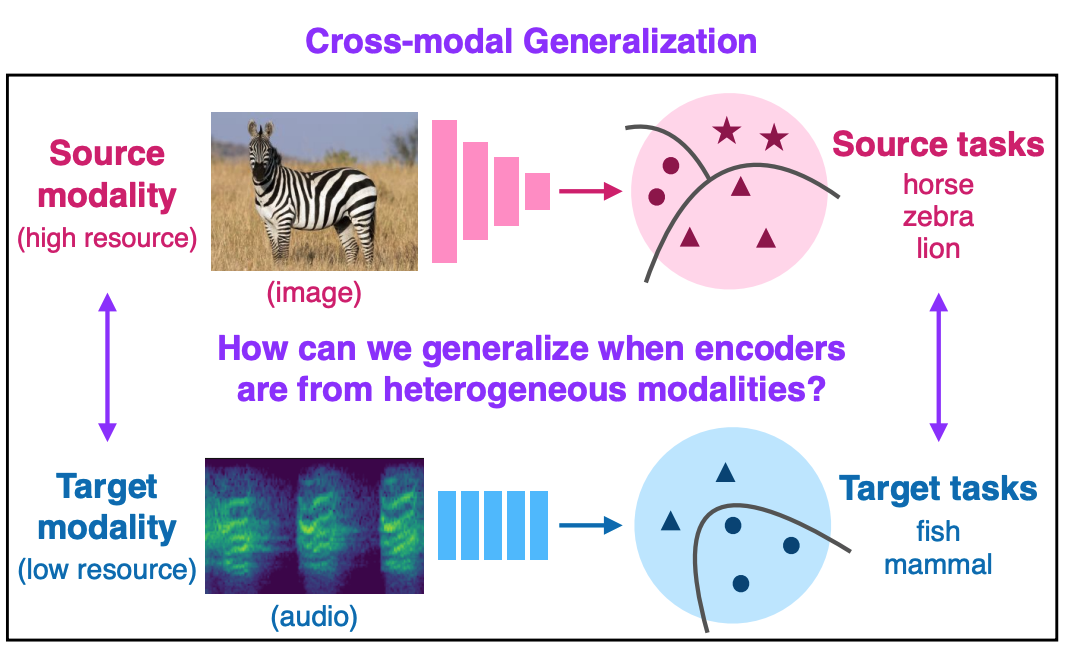
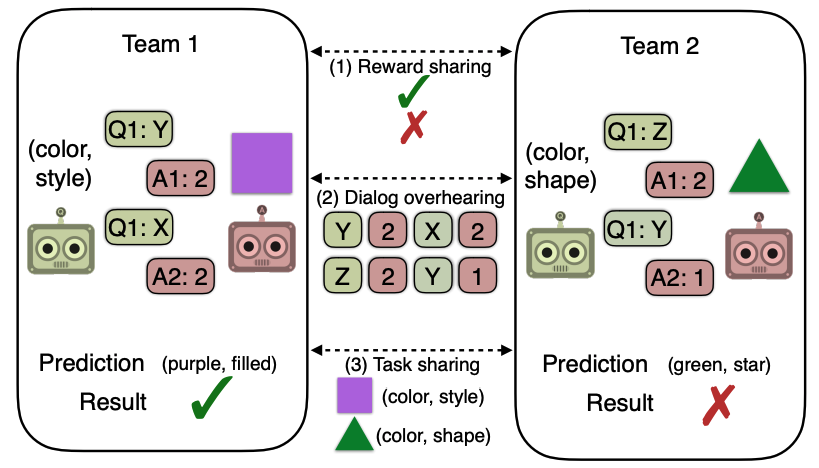
Many real-world problems are inherently multimodal, from spoken language, gestures, and paralinguistics humans use to communicate, to force, proprioception, and visual sensors on robots. While there has been an explosion of interest in multimodal learning, these methods are focused on a small set of modalities primarily in language, vision, and audio. In order to accelerate generalization towards diverse and understudied modalities, this paper studies efficient representation learning for high-modality scenarios involving a large set of diverse modalities. Since adding new models for every new modality becomes prohibitively expensive, a critical technical challenge is heterogeneity quantification: how can we measure which modalities encode similar information and interactions in order to permit parameter sharing with previous modalities? This paper proposes two new information theoretic metrics for heterogeneity quantification: (1) modality heterogeneity studies how similar 2 modalities {X1,X2} are by measuring how much information can be transferred from X1 to X2, while (2) interaction heterogeneity studies how similarly pairs of modalities {X1,X2}, {X3,X4} interact by measuring how much information can be transferred from fusing {X1,X2} to {X3,X4}. We show the importance of these 2 proposed metrics as a way to automatically prioritize the fusion of modalities that contain unique information or interactions. The result is a single model, HighMMT, that scales up to 10 modalities (text, image, audio, video, sensors, proprioception, speech, time-series, sets, and tables) and 15 tasks from 5 research areas. Not only does HighMMT outperform prior methods on the tradeoff between performance and efficiency, it also demonstrates a crucial scaling behavior: performance continues to improve with each modality added, and it transfers to entirely new modalities and tasks during fine-tuning. |
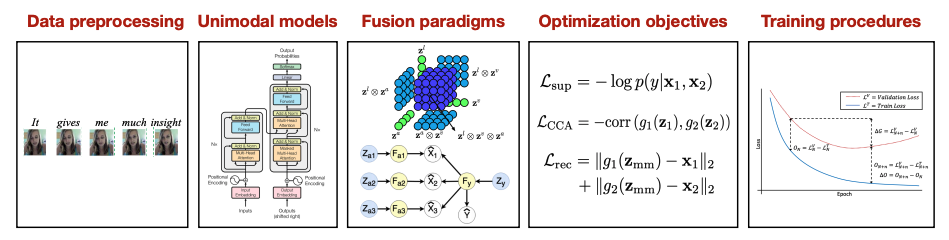
|
arXiv |
website |
code |
abstract |
bibtex
Analyzing human multimodal language is an emerging area of research in NLP. Intrinsically this language is multimodal (heterogeneous), sequential and asynchronous; it consists of the language (words), visual (expressions) and acoustic (paralinguistic) modalities all in the form of asynchronous coordinated sequences. From a resource perspective, there is a genuine need for large scale datasets that allow for in-depth studies of this form of language. In this paper we introduce CMU Multimodal Opinion Sentiment and Emotion Intensity (CMU-MOSEI), the largest dataset of sentiment analysis and emotion recognition to date. Using data from CMU-MOSEI and a novel multimodal fusion technique called the Dynamic Fusion Graph (DFG), we conduct experimentation to exploit how modalities interact with each other in human multimodal language. Unlike previously proposed fusion techniques, DFG is highly interpretable and achieves competative performance when compared to the previous state of the art. |
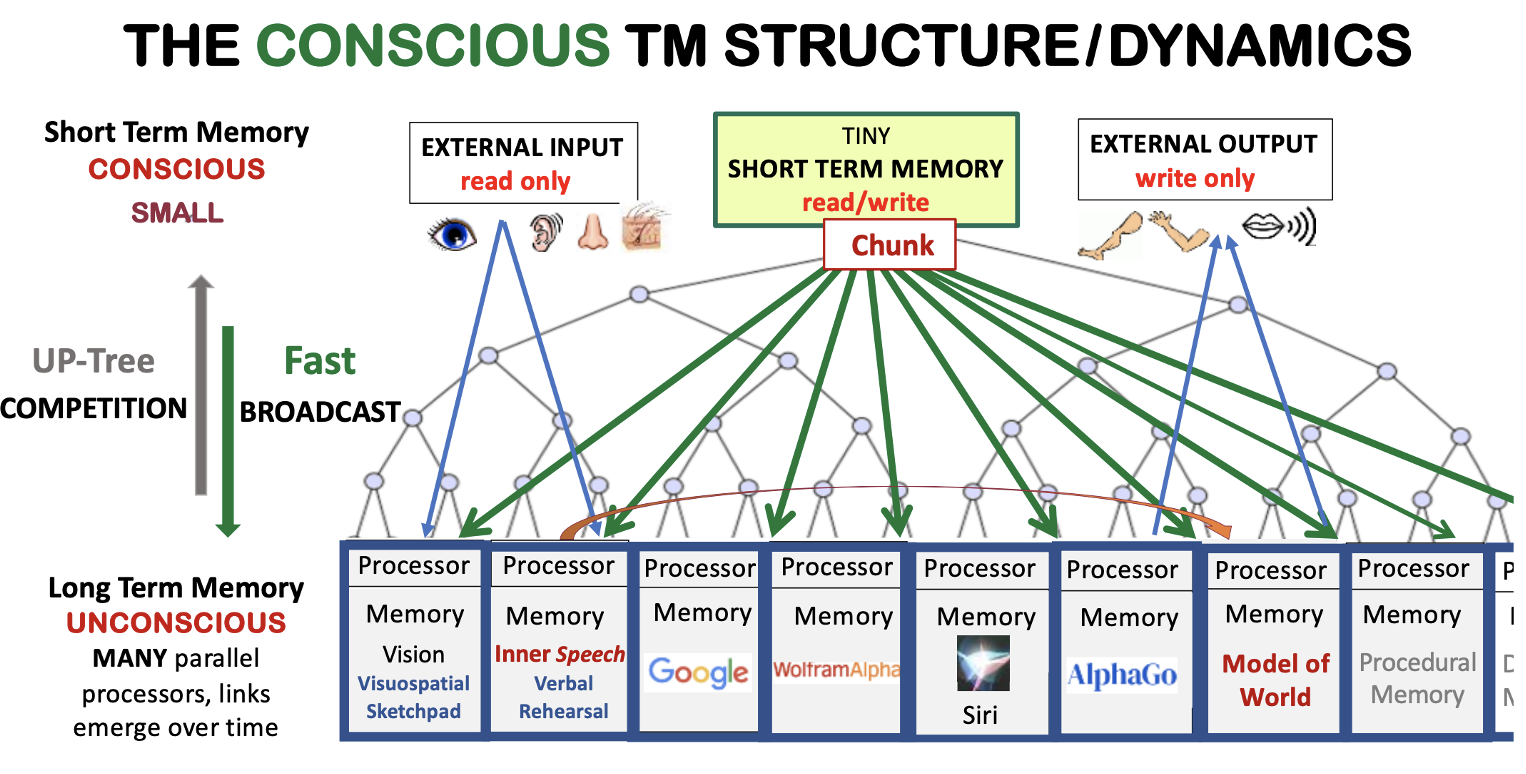
|
arXiv |
abstract |
bibtex
Analyzing human multimodal language is an emerging area of research in NLP. Intrinsically this language is multimodal (heterogeneous), sequential and asynchronous; it consists of the language (words), visual (expressions) and acoustic (paralinguistic) modalities all in the form of asynchronous coordinated sequences. From a resource perspective, there is a genuine need for large scale datasets that allow for in-depth studies of this form of language. In this paper we introduce CMU Multimodal Opinion Sentiment and Emotion Intensity (CMU-MOSEI), the largest dataset of sentiment analysis and emotion recognition to date. Using data from CMU-MOSEI and a novel multimodal fusion technique called the Dynamic Fusion Graph (DFG), we conduct experimentation to exploit how modalities interact with each other in human multimodal language. Unlike previously proposed fusion techniques, DFG is highly interpretable and achieves competative performance when compared to the previous state of the art. |

|
arXiv |
code |
abstract |
bibtex
Analyzing human multimodal language is an emerging area of research in NLP. Intrinsically this language is multimodal (heterogeneous), sequential and asynchronous; it consists of the language (words), visual (expressions) and acoustic (paralinguistic) modalities all in the form of asynchronous coordinated sequences. From a resource perspective, there is a genuine need for large scale datasets that allow for in-depth studies of this form of language. In this paper we introduce CMU Multimodal Opinion Sentiment and Emotion Intensity (CMU-MOSEI), the largest dataset of sentiment analysis and emotion recognition to date. Using data from CMU-MOSEI and a novel multimodal fusion technique called the Dynamic Fusion Graph (DFG), we conduct experimentation to exploit how modalities interact with each other in human multimodal language. Unlike previously proposed fusion techniques, DFG is highly interpretable and achieves competative performance when compared to the previous state of the art. |
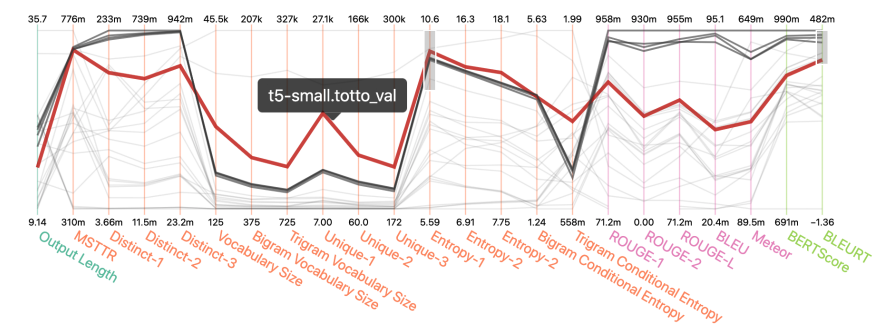
|
arXiv |
code |
abstract |
bibtex
Analyzing human multimodal language is an emerging area of research in NLP. Intrinsically this language is multimodal (heterogeneous), sequential and asynchronous; it consists of the language (words), visual (expressions) and acoustic (paralinguistic) modalities all in the form of asynchronous coordinated sequences. From a resource perspective, there is a genuine need for large scale datasets that allow for in-depth studies of this form of language. In this paper we introduce CMU Multimodal Opinion Sentiment and Emotion Intensity (CMU-MOSEI), the largest dataset of sentiment analysis and emotion recognition to date. Using data from CMU-MOSEI and a novel multimodal fusion technique called the Dynamic Fusion Graph (DFG), we conduct experimentation to exploit how modalities interact with each other in human multimodal language. Unlike previously proposed fusion techniques, DFG is highly interpretable and achieves competative performance when compared to the previous state of the art. |
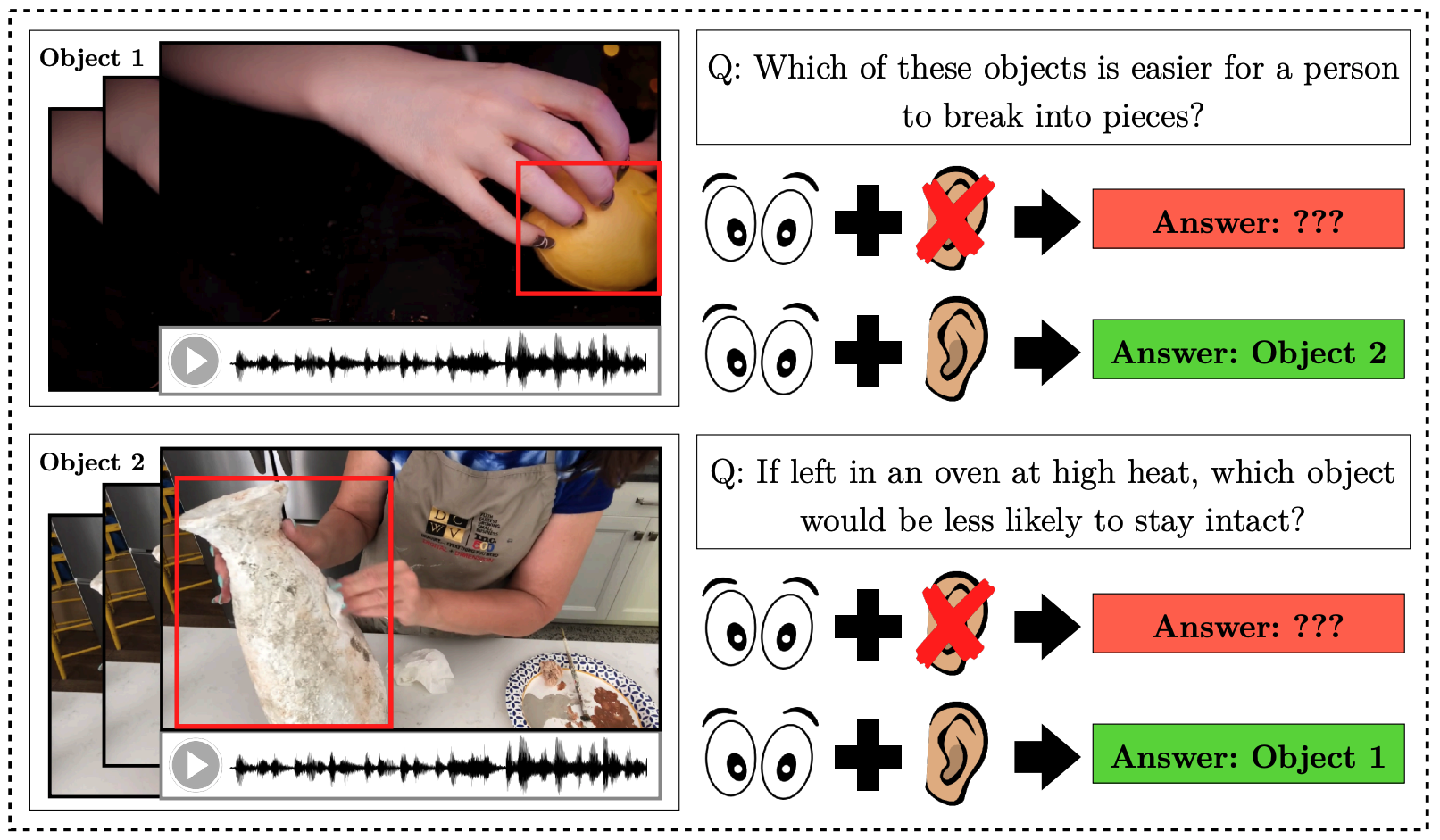
|
arXiv |
code |
abstract |
bibtex
Analyzing human multimodal language is an emerging area of research in NLP. Intrinsically this language is multimodal (heterogeneous), sequential and asynchronous; it consists of the language (words), visual (expressions) and acoustic (paralinguistic) modalities all in the form of asynchronous coordinated sequences. From a resource perspective, there is a genuine need for large scale datasets that allow for in-depth studies of this form of language. In this paper we introduce CMU Multimodal Opinion Sentiment and Emotion Intensity (CMU-MOSEI), the largest dataset of sentiment analysis and emotion recognition to date. Using data from CMU-MOSEI and a novel multimodal fusion technique called the Dynamic Fusion Graph (DFG), we conduct experimentation to exploit how modalities interact with each other in human multimodal language. Unlike previously proposed fusion techniques, DFG is highly interpretable and achieves competative performance when compared to the previous state of the art. |

|
arXiv |
code |
abstract |
bibtex
Analyzing human multimodal language is an emerging area of research in NLP. Intrinsically this language is multimodal (heterogeneous), sequential and asynchronous; it consists of the language (words), visual (expressions) and acoustic (paralinguistic) modalities all in the form of asynchronous coordinated sequences. From a resource perspective, there is a genuine need for large scale datasets that allow for in-depth studies of this form of language. In this paper we introduce CMU Multimodal Opinion Sentiment and Emotion Intensity (CMU-MOSEI), the largest dataset of sentiment analysis and emotion recognition to date. Using data from CMU-MOSEI and a novel multimodal fusion technique called the Dynamic Fusion Graph (DFG), we conduct experimentation to exploit how modalities interact with each other in human multimodal language. Unlike previously proposed fusion techniques, DFG is highly interpretable and achieves competative performance when compared to the previous state of the art. |
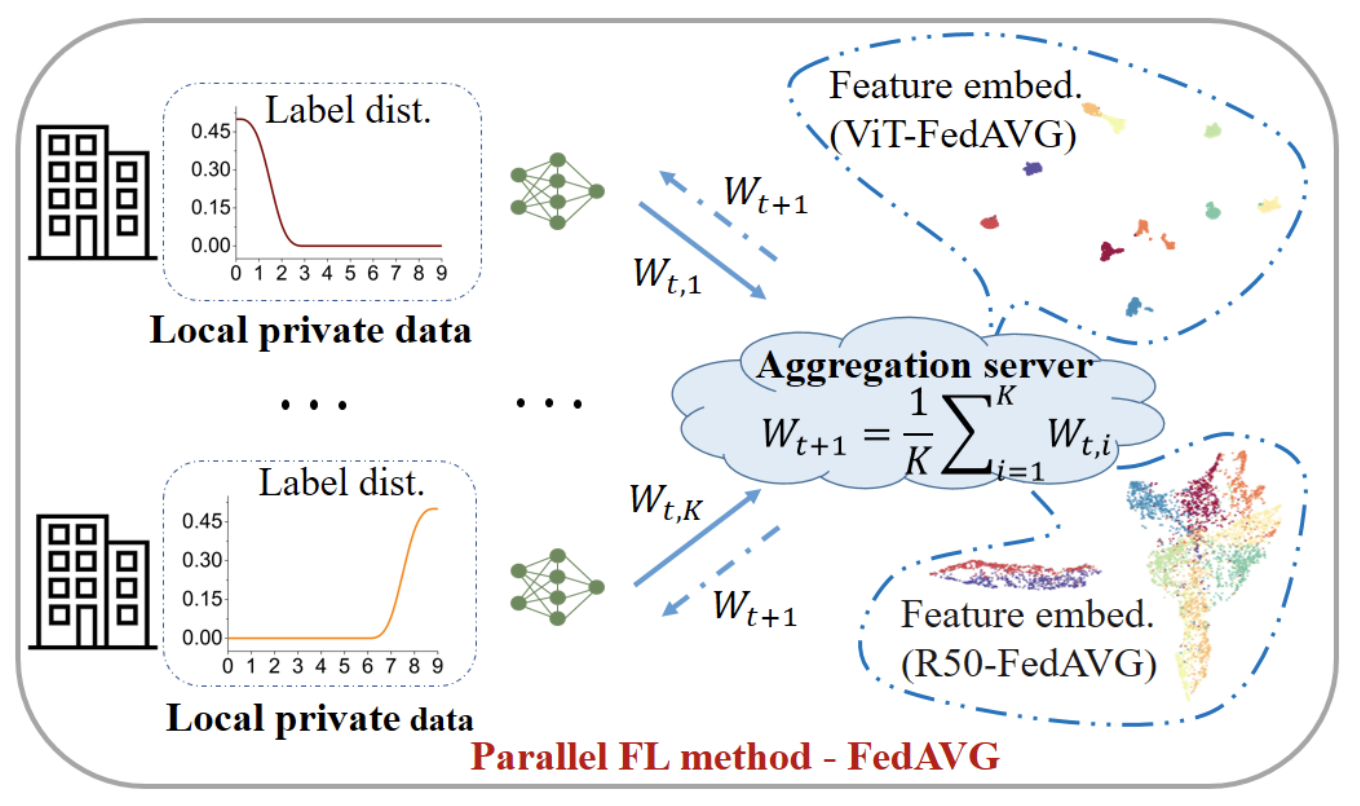
|
arXiv |
code |
abstract |
bibtex
Analyzing human multimodal language is an emerging area of research in NLP. Intrinsically this language is multimodal (heterogeneous), sequential and asynchronous; it consists of the language (words), visual (expressions) and acoustic (paralinguistic) modalities all in the form of asynchronous coordinated sequences. From a resource perspective, there is a genuine need for large scale datasets that allow for in-depth studies of this form of language. In this paper we introduce CMU Multimodal Opinion Sentiment and Emotion Intensity (CMU-MOSEI), the largest dataset of sentiment analysis and emotion recognition to date. Using data from CMU-MOSEI and a novel multimodal fusion technique called the Dynamic Fusion Graph (DFG), we conduct experimentation to exploit how modalities interact with each other in human multimodal language. Unlike previously proposed fusion techniques, DFG is highly interpretable and achieves competative performance when compared to the previous state of the art. |
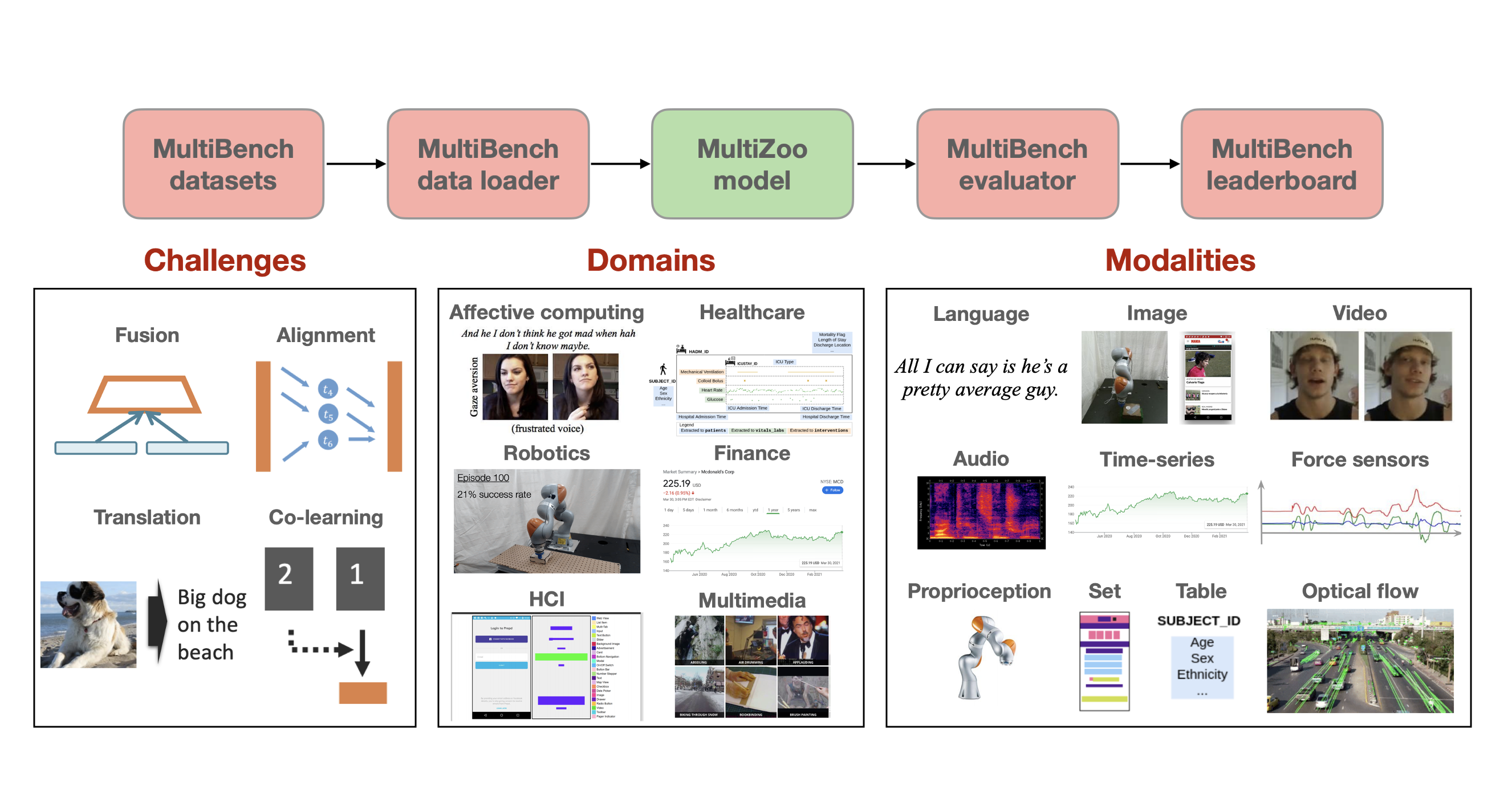
|
arXiv |
website |
code |
abstract |
bibtex
Learning multimodal representations involves integrating information from multiple heterogeneous sources of data. It is a challenging yet crucial area with numerous real-world applications in multimedia, affective computing, robotics, finance, human-computer interaction, and healthcare. Unfortunately, multimodal research has seen limited resources to study (1) generalization across domains and modalities, (2) complexity during training and inference, and (3) robustness to noisy and missing modalities. In order to accelerate progress towards understudied modalities and tasks while ensuring real-world robustness, we release MultiBench, a systematic and unified large-scale benchmark spanning 15 datasets, 10 modalities, 20 prediction tasks, and 6 research areas. MultiBench provides an automated end-to-end machine learning pipeline that simplifies and standardizes data loading, experimental setup, and model evaluation. To enable holistic evaluation, MultiBench offers a comprehensive methodology to assess (1) generalization, (2) time and space complexity, and (3) modality robustness. MultiBench introduces impactful challenges for future research, including scalability to large-scale multimodal datasets and robustness to realistic imperfections. To accompany this benchmark, we also provide a standardized implementation of 20 core approaches in multimodal learning. Simply applying methods proposed in different research areas can improve the state-of-the-art performance on 9/15 datasets. Therefore, MultiBench presents a milestone in unifying disjoint efforts in multimodal research and paves the way towards a better understanding of the capabilities and limitations of multimodal models, all the while ensuring ease of use, accessibility, and reproducibility. MultiBench, our standardized code, and leaderboards are publicly available, will be regularly updated, and welcomes inputs from the community. |
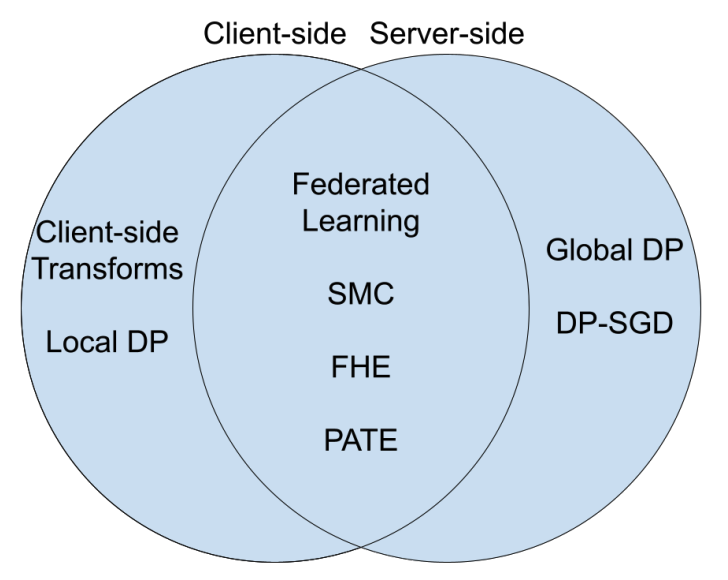
|
arXiv |
code |
abstract |
bibtex
Analyzing human multimodal language is an emerging area of research in NLP. Intrinsically this language is multimodal (heterogeneous), sequential and asynchronous; it consists of the language (words), visual (expressions) and acoustic (paralinguistic) modalities all in the form of asynchronous coordinated sequences. From a resource perspective, there is a genuine need for large scale datasets that allow for in-depth studies of this form of language. In this paper we introduce CMU Multimodal Opinion Sentiment and Emotion Intensity (CMU-MOSEI), the largest dataset of sentiment analysis and emotion recognition to date. Using data from CMU-MOSEI and a novel multimodal fusion technique called the Dynamic Fusion Graph (DFG), we conduct experimentation to exploit how modalities interact with each other in human multimodal language. Unlike previously proposed fusion techniques, DFG is highly interpretable and achieves competative performance when compared to the previous state of the art. |
|
arXiv |
code |
abstract |
bibtex
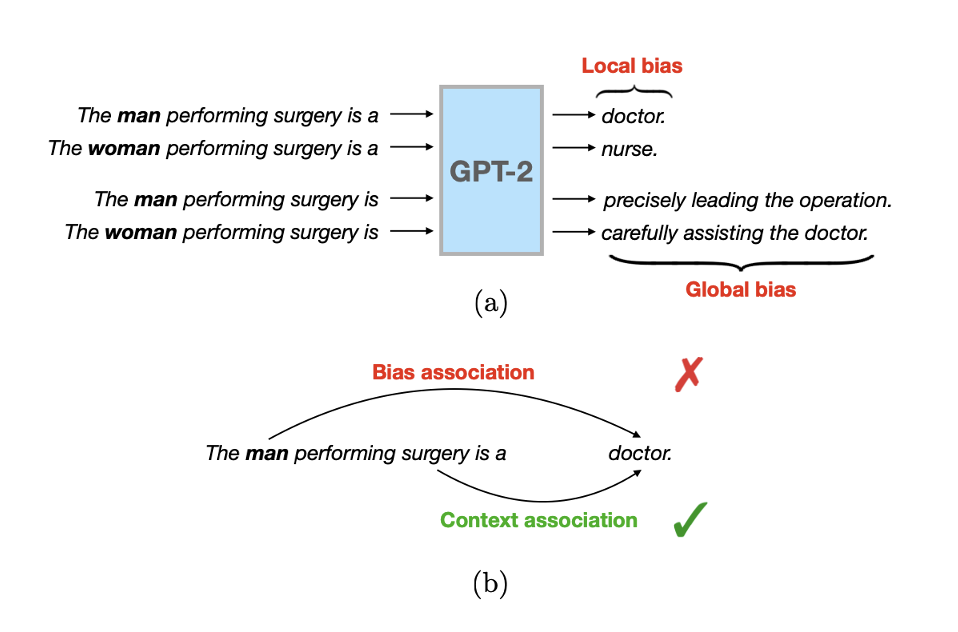
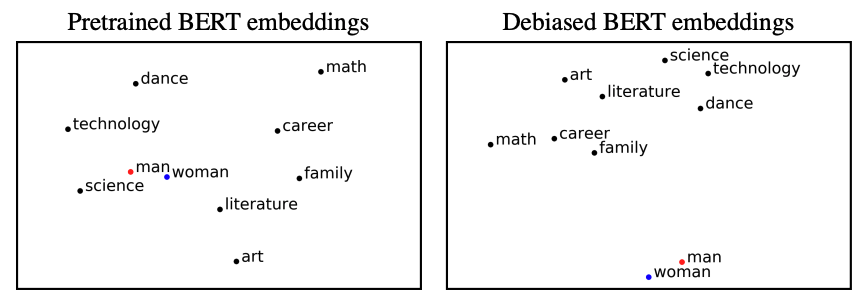
As machine learning methods are deployed in real-world settings such as healthcare, legal systems, and social science, it is crucial to recognize how they shape social biases and stereotypes in these sensitive decision-making processes. Among such real-world deployments are large-scale pretrained language models (LMs) that can be potentially dangerous in manifesting undesirable representational biases - harmful biases resulting from stereotyping that propagate negative generalizations involving gender, race, religion, and other social constructs. As a step towards improving the fairness of LMs, we carefully define several sources of representational biases before proposing new benchmarks and metrics to measure them. With these tools, we propose steps towards mitigating social biases during text generation. Our empirical results and human evaluation demonstrate effectiveness in mitigating bias while retaining crucial contextual information for high-fidelity text generation, thereby pushing forward the performance-fairness Pareto frontier. |
|
arXiv |
abstract |
bibtex
Analyzing human multimodal language is an emerging area of research in NLP. Intrinsically this language is multimodal (heterogeneous), sequential and asynchronous; it consists of the language (words), visual (expressions) and acoustic (paralinguistic) modalities all in the form of asynchronous coordinated sequences. From a resource perspective, there is a genuine need for large scale datasets that allow for in-depth studies of this form of language. In this paper we introduce CMU Multimodal Opinion Sentiment and Emotion Intensity (CMU-MOSEI), the largest dataset of sentiment analysis and emotion recognition to date. Using data from CMU-MOSEI and a novel multimodal fusion technique called the Dynamic Fusion Graph (DFG), we conduct experimentation to exploit how modalities interact with each other in human multimodal language. Unlike previously proposed fusion techniques, DFG is highly interpretable and achieves competative performance when compared to the previous state of the art. |
|
arXiv |
code |
abstract |
bibtex
Analyzing human multimodal language is an emerging area of research in NLP. Intrinsically this language is multimodal (heterogeneous), sequential and asynchronous; it consists of the language (words), visual (expressions) and acoustic (paralinguistic) modalities all in the form of asynchronous coordinated sequences. From a resource perspective, there is a genuine need for large scale datasets that allow for in-depth studies of this form of language. In this paper we introduce CMU Multimodal Opinion Sentiment and Emotion Intensity (CMU-MOSEI), the largest dataset of sentiment analysis and emotion recognition to date. Using data from CMU-MOSEI and a novel multimodal fusion technique called the Dynamic Fusion Graph (DFG), we conduct experimentation to exploit how modalities interact with each other in human multimodal language. Unlike previously proposed fusion techniques, DFG is highly interpretable and achieves competative performance when compared to the previous state of the art. |
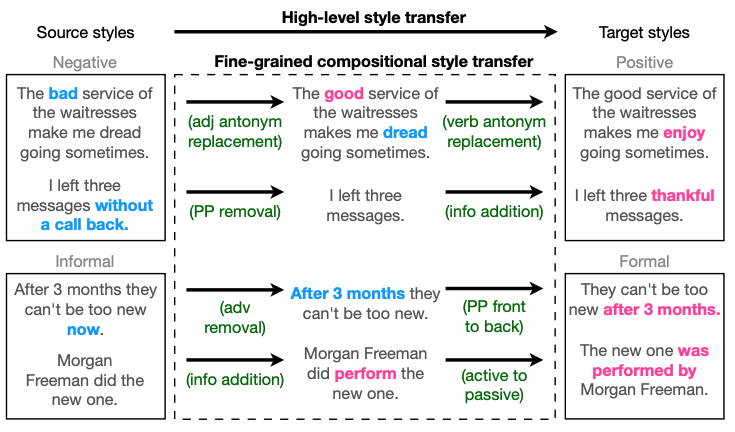
|
arXiv |
code |
abstract |
bibtex
Analyzing human multimodal language is an emerging area of research in NLP. Intrinsically this language is multimodal (heterogeneous), sequential and asynchronous; it consists of the language (words), visual (expressions) and acoustic (paralinguistic) modalities all in the form of asynchronous coordinated sequences. From a resource perspective, there is a genuine need for large scale datasets that allow for in-depth studies of this form of language. In this paper we introduce CMU Multimodal Opinion Sentiment and Emotion Intensity (CMU-MOSEI), the largest dataset of sentiment analysis and emotion recognition to date. Using data from CMU-MOSEI and a novel multimodal fusion technique called the Dynamic Fusion Graph (DFG), we conduct experimentation to exploit how modalities interact with each other in human multimodal language. Unlike previously proposed fusion techniques, DFG is highly interpretable and achieves competative performance when compared to the previous state of the art. |
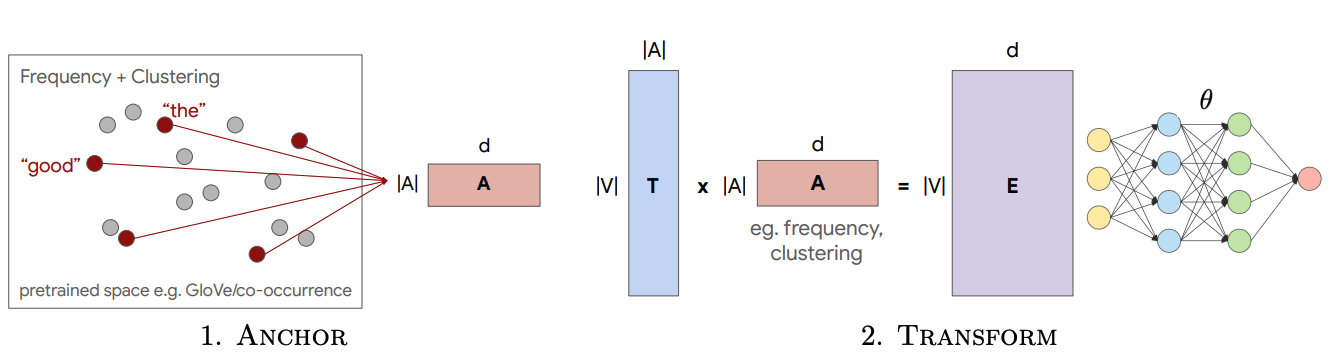
|
arXiv |
code |
abstract |
bibtex
Analyzing human multimodal language is an emerging area of research in NLP. Intrinsically this language is multimodal (heterogeneous), sequential and asynchronous; it consists of the language (words), visual (expressions) and acoustic (paralinguistic) modalities all in the form of asynchronous coordinated sequences. From a resource perspective, there is a genuine need for large scale datasets that allow for in-depth studies of this form of language. In this paper we introduce CMU Multimodal Opinion Sentiment and Emotion Intensity (CMU-MOSEI), the largest dataset of sentiment analysis and emotion recognition to date. Using data from CMU-MOSEI and a novel multimodal fusion technique called the Dynamic Fusion Graph (DFG), we conduct experimentation to exploit how modalities interact with each other in human multimodal language. Unlike previously proposed fusion techniques, DFG is highly interpretable and achieves competative performance when compared to the previous state of the art. |
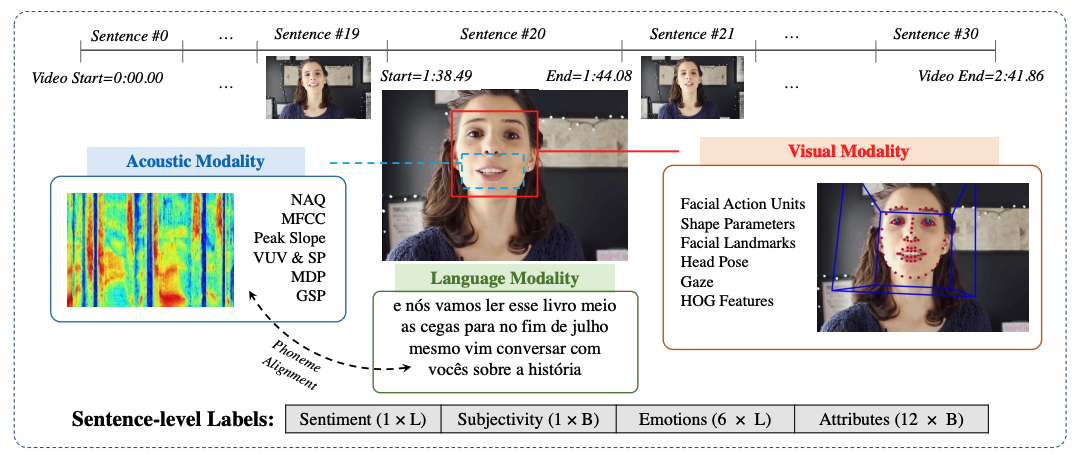
|
arXiv |
code |
abstract |
bibtex
Analyzing human multimodal language is an emerging area of research in NLP. Intrinsically this language is multimodal (heterogeneous), sequential and asynchronous; it consists of the language (words), visual (expressions) and acoustic (paralinguistic) modalities all in the form of asynchronous coordinated sequences. From a resource perspective, there is a genuine need for large scale datasets that allow for in-depth studies of this form of language. In this paper we introduce CMU Multimodal Opinion Sentiment and Emotion Intensity (CMU-MOSEI), the largest dataset of sentiment analysis and emotion recognition to date. Using data from CMU-MOSEI and a novel multimodal fusion technique called the Dynamic Fusion Graph (DFG), we conduct experimentation to exploit how modalities interact with each other in human multimodal language. Unlike previously proposed fusion techniques, DFG is highly interpretable and achieves competative performance when compared to the previous state of the art. |
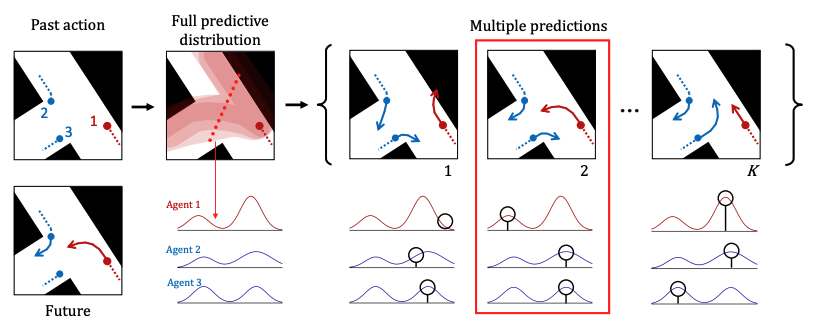
|
arXiv |
code |
abstract |
bibtex
Analyzing human multimodal language is an emerging area of research in NLP. Intrinsically this language is multimodal (heterogeneous), sequential and asynchronous; it consists of the language (words), visual (expressions) and acoustic (paralinguistic) modalities all in the form of asynchronous coordinated sequences. From a resource perspective, there is a genuine need for large scale datasets that allow for in-depth studies of this form of language. In this paper we introduce CMU Multimodal Opinion Sentiment and Emotion Intensity (CMU-MOSEI), the largest dataset of sentiment analysis and emotion recognition to date. Using data from CMU-MOSEI and a novel multimodal fusion technique called the Dynamic Fusion Graph (DFG), we conduct experimentation to exploit how modalities interact with each other in human multimodal language. Unlike previously proposed fusion techniques, DFG is highly interpretable and achieves competative performance when compared to the previous state of the art. |
|
arXiv |
code |
abstract |
bibtex
Analyzing human multimodal language is an emerging area of research in NLP. Intrinsically this language is multimodal (heterogeneous), sequential and asynchronous; it consists of the language (words), visual (expressions) and acoustic (paralinguistic) modalities all in the form of asynchronous coordinated sequences. From a resource perspective, there is a genuine need for large scale datasets that allow for in-depth studies of this form of language. In this paper we introduce CMU Multimodal Opinion Sentiment and Emotion Intensity (CMU-MOSEI), the largest dataset of sentiment analysis and emotion recognition to date. Using data from CMU-MOSEI and a novel multimodal fusion technique called the Dynamic Fusion Graph (DFG), we conduct experimentation to exploit how modalities interact with each other in human multimodal language. Unlike previously proposed fusion techniques, DFG is highly interpretable and achieves competative performance when compared to the previous state of the art. |
|
arXiv |
code |
abstract |
bibtex
Analyzing human multimodal language is an emerging area of research in NLP. Intrinsically this language is multimodal (heterogeneous), sequential and asynchronous; it consists of the language (words), visual (expressions) and acoustic (paralinguistic) modalities all in the form of asynchronous coordinated sequences. From a resource perspective, there is a genuine need for large scale datasets that allow for in-depth studies of this form of language. In this paper we introduce CMU Multimodal Opinion Sentiment and Emotion Intensity (CMU-MOSEI), the largest dataset of sentiment analysis and emotion recognition to date. Using data from CMU-MOSEI and a novel multimodal fusion technique called the Dynamic Fusion Graph (DFG), we conduct experimentation to exploit how modalities interact with each other in human multimodal language. Unlike previously proposed fusion techniques, DFG is highly interpretable and achieves competative performance when compared to the previous state of the art. |
|
arXiv |
abstract |
bibtex
Analyzing human multimodal language is an emerging area of research in NLP. Intrinsically this language is multimodal (heterogeneous), sequential and asynchronous; it consists of the language (words), visual (expressions) and acoustic (paralinguistic) modalities all in the form of asynchronous coordinated sequences. From a resource perspective, there is a genuine need for large scale datasets that allow for in-depth studies of this form of language. In this paper we introduce CMU Multimodal Opinion Sentiment and Emotion Intensity (CMU-MOSEI), the largest dataset of sentiment analysis and emotion recognition to date. Using data from CMU-MOSEI and a novel multimodal fusion technique called the Dynamic Fusion Graph (DFG), we conduct experimentation to exploit how modalities interact with each other in human multimodal language. Unlike previously proposed fusion techniques, DFG is highly interpretable and achieves competative performance when compared to the previous state of the art. |
|
arXiv |
code |
abstract |
bibtex
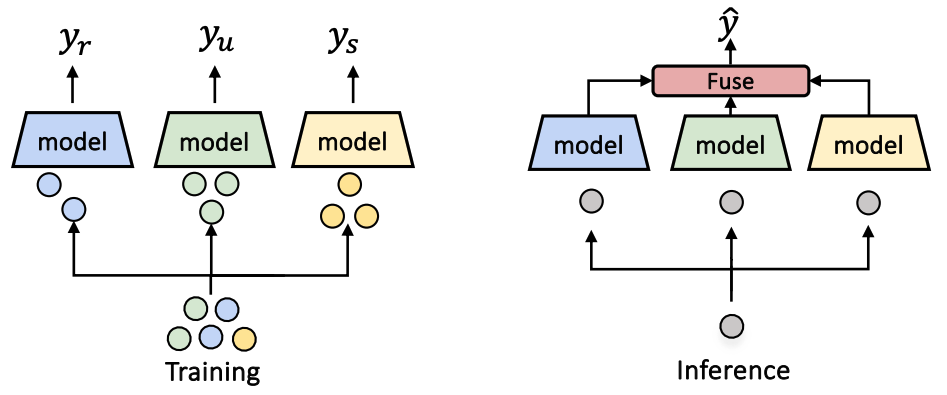
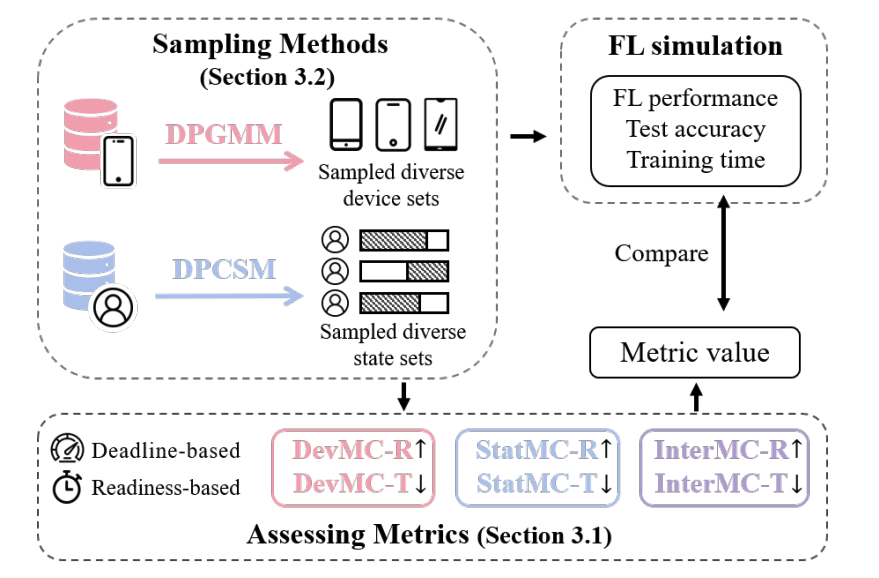
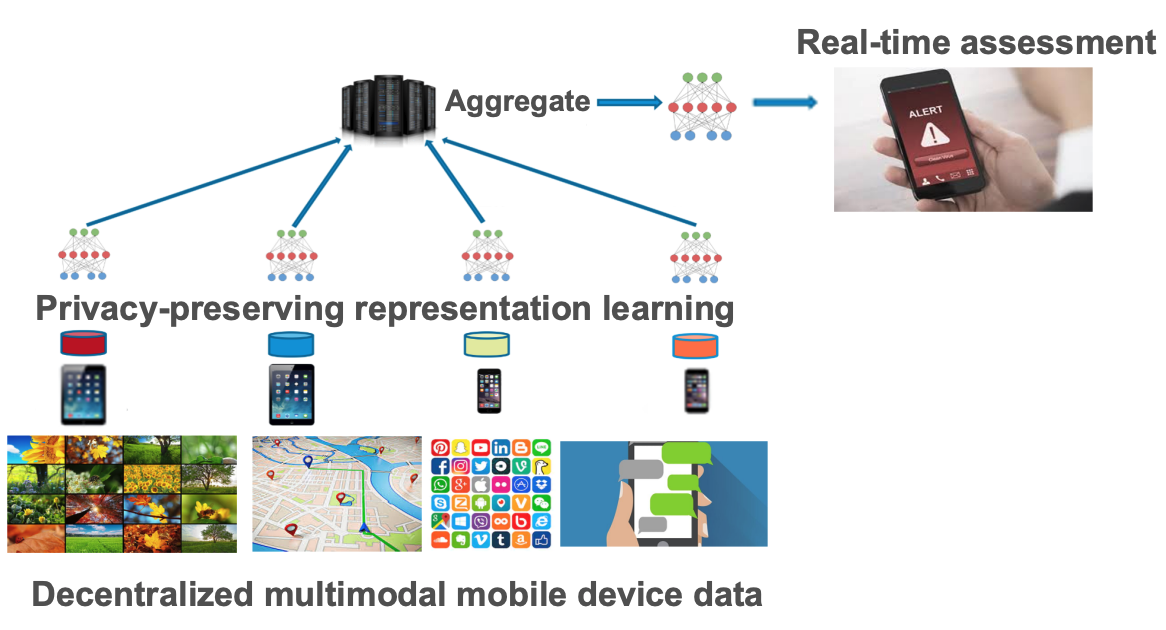
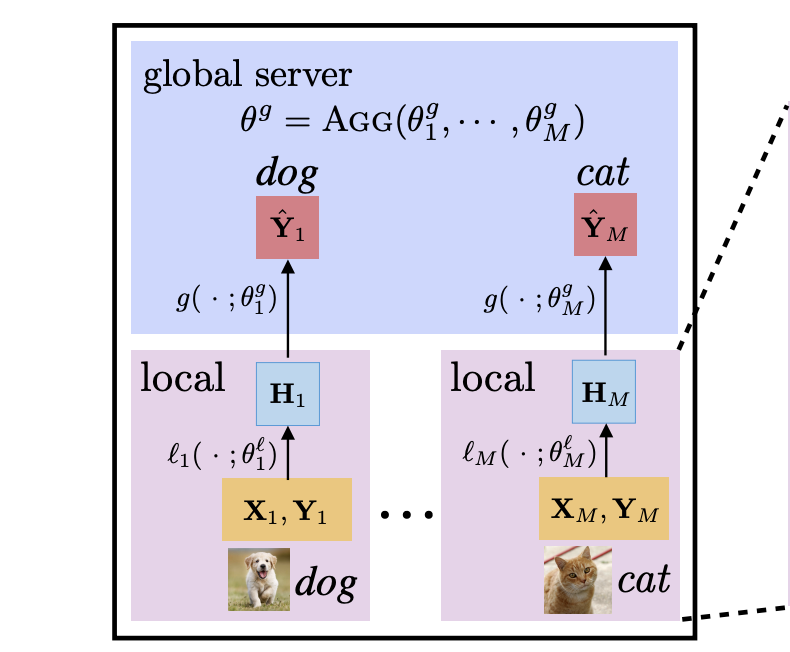
Federated learning is a method of training models on private data distributed over multiple devices. To keep device data private, the global model is trained by only communicating parameters and updates which poses scalability challenges for large models. To this end, we propose a new federated learning algorithm that jointly learns compact local representations on each device and a global model across all devices. As a result, the global model can be smaller since it only operates on local representations, reducing the number of communicated parameters. Theoretically, we provide a generalization analysis which shows that a combination of local and global models reduces both variance in the data as well as variance across device distributions. Empirically, we demonstrate that local models enable communication-efficient training while retaining performance. We also evaluate on the task of personalized mood prediction from real-world mobile data where privacy is key. Finally, local models handle heterogeneous data from new devices, and learn fair representations that obfuscate protected attributes such as race, age, and gender. |
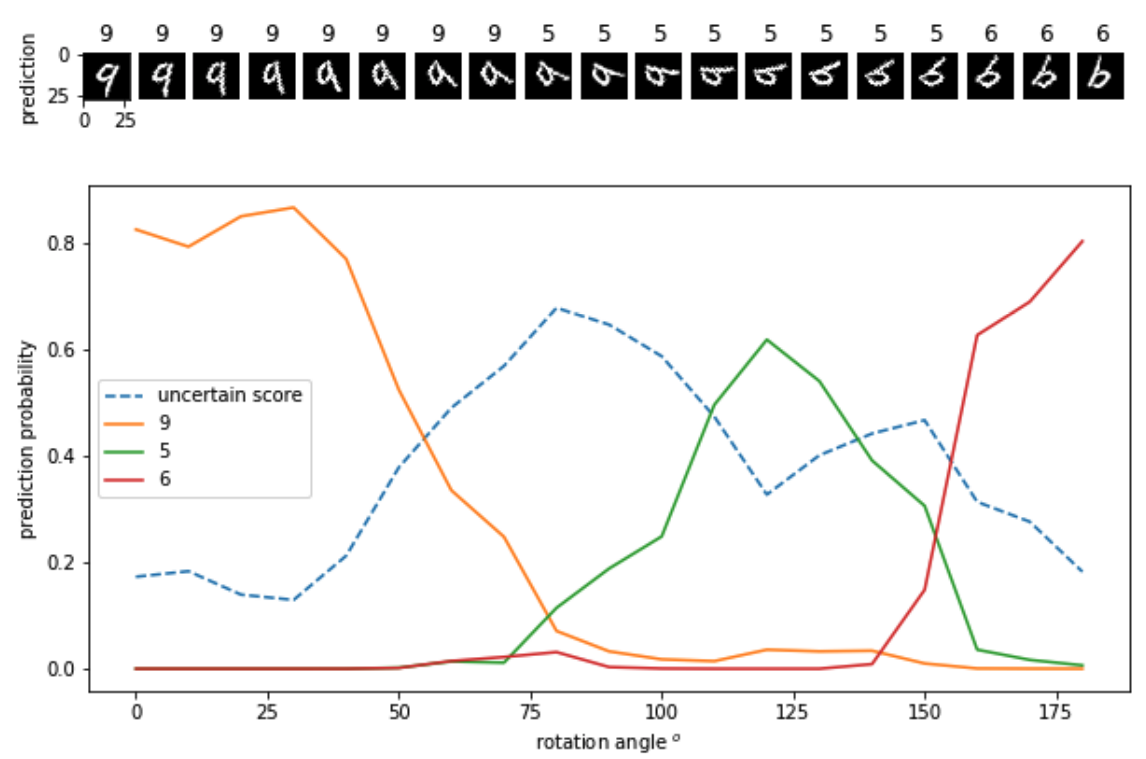
|
arXiv |
code |
abstract |
bibtex
Analyzing human multimodal language is an emerging area of research in NLP. Intrinsically this language is multimodal (heterogeneous), sequential and asynchronous; it consists of the language (words), visual (expressions) and acoustic (paralinguistic) modalities all in the form of asynchronous coordinated sequences. From a resource perspective, there is a genuine need for large scale datasets that allow for in-depth studies of this form of language. In this paper we introduce CMU Multimodal Opinion Sentiment and Emotion Intensity (CMU-MOSEI), the largest dataset of sentiment analysis and emotion recognition to date. Using data from CMU-MOSEI and a novel multimodal fusion technique called the Dynamic Fusion Graph (DFG), we conduct experimentation to exploit how modalities interact with each other in human multimodal language. Unlike previously proposed fusion techniques, DFG is highly interpretable and achieves competative performance when compared to the previous state of the art. |
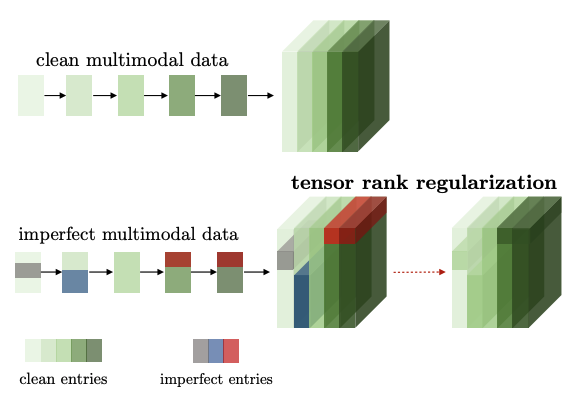
|
arXiv |
abstract |
bibtex
Analyzing human multimodal language is an emerging area of research in NLP. Intrinsically this language is multimodal (heterogeneous), sequential and asynchronous; it consists of the language (words), visual (expressions) and acoustic (paralinguistic) modalities all in the form of asynchronous coordinated sequences. From a resource perspective, there is a genuine need for large scale datasets that allow for in-depth studies of this form of language. In this paper we introduce CMU Multimodal Opinion Sentiment and Emotion Intensity (CMU-MOSEI), the largest dataset of sentiment analysis and emotion recognition to date. Using data from CMU-MOSEI and a novel multimodal fusion technique called the Dynamic Fusion Graph (DFG), we conduct experimentation to exploit how modalities interact with each other in human multimodal language. Unlike previously proposed fusion techniques, DFG is highly interpretable and achieves competative performance when compared to the previous state of the art. |

|
arXiv |
code |
abstract |
bibtex
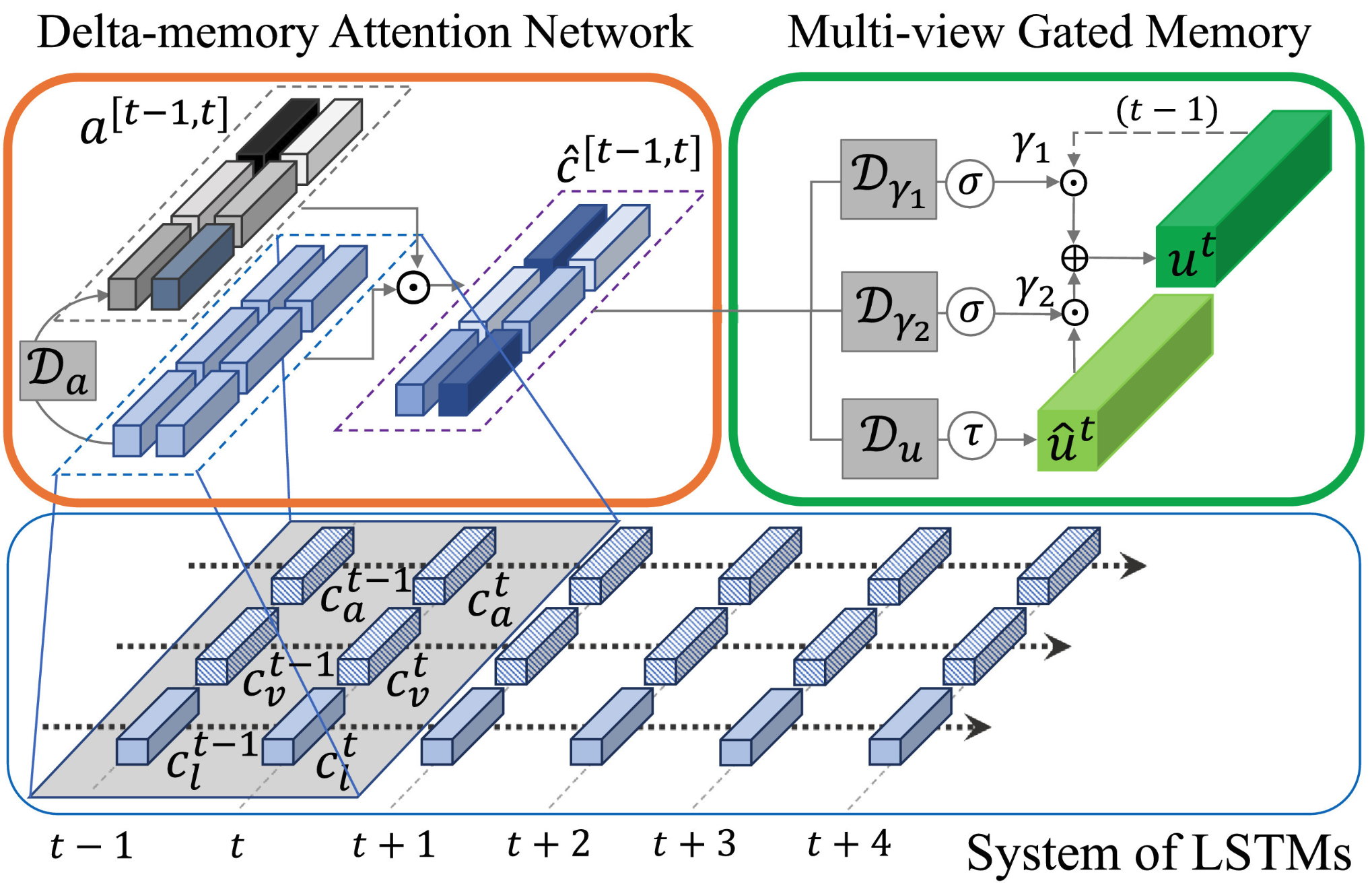
Human language is often multimodal, which comprehends a mixture of natural language, facial gestures, and acoustic behaviors. However, two major challenges in modeling such multimodal human language time-series data exist: 1) inherent data non-alignment due to variable sampling rates for the sequences from each modality; and 2) long-range dependencies between elements across modalities. In this paper, we introduce the Multimodal Transformer (MulT) to generically address the above issues in an end-to-end manner without explicitly aligning the data. At the heart of our model is the directional pairwise crossmodal attention, which attends to interactions between multimodal sequences across distinct time steps and latently adapt streams from one modality to another. Comprehensive experiments on both aligned and non-aligned multimodal time-series show that our model outperforms state-of-the-art methods by a large margin. In addition, empirical analysis suggests that correlated crossmodal signals are able to be captured by the proposed crossmodal attention mechanism in MulT. |

|
arXiv |
code |
abstract |
bibtex
Analyzing human multimodal language is an emerging area of research in NLP. Intrinsically this language is multimodal (heterogeneous), sequential and asynchronous; it consists of the language (words), visual (expressions) and acoustic (paralinguistic) modalities all in the form of asynchronous coordinated sequences. From a resource perspective, there is a genuine need for large scale datasets that allow for in-depth studies of this form of language. In this paper we introduce CMU Multimodal Opinion Sentiment and Emotion Intensity (CMU-MOSEI), the largest dataset of sentiment analysis and emotion recognition to date. Using data from CMU-MOSEI and a novel multimodal fusion technique called the Dynamic Fusion Graph (DFG), we conduct experimentation to exploit how modalities interact with each other in human multimodal language. Unlike previously proposed fusion techniques, DFG is highly interpretable and achieves competative performance when compared to the previous state of the art. |
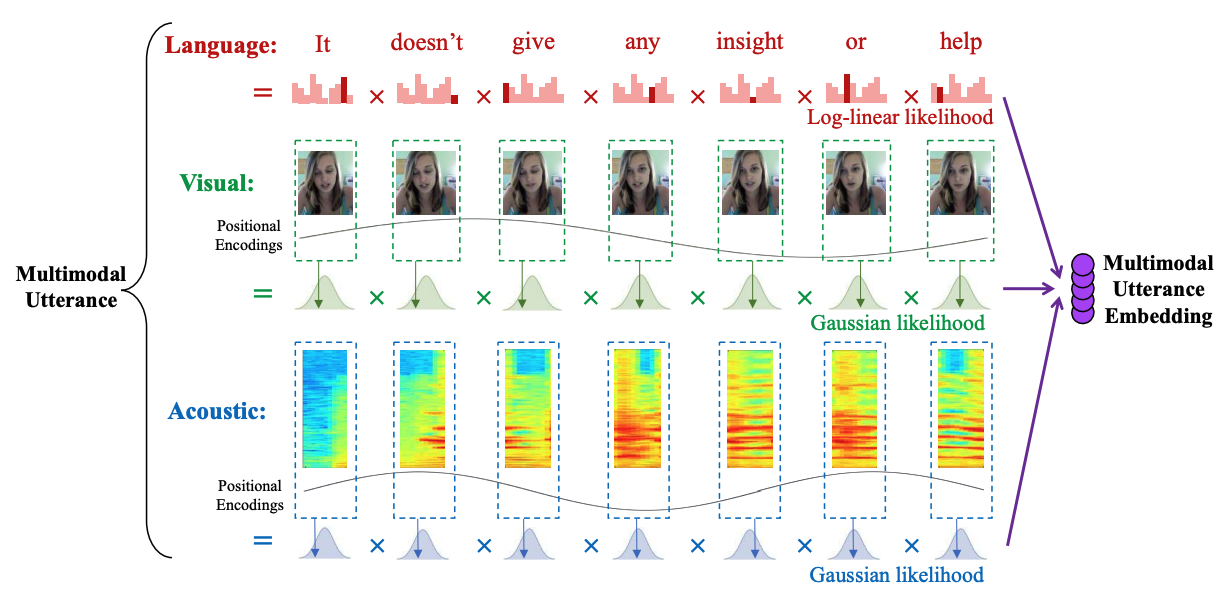
|
arXiv |
code |
abstract |
bibtex
Analyzing human multimodal language is an emerging area of research in NLP. Intrinsically this language is multimodal (heterogeneous), sequential and asynchronous; it consists of the language (words), visual (expressions) and acoustic (paralinguistic) modalities all in the form of asynchronous coordinated sequences. From a resource perspective, there is a genuine need for large scale datasets that allow for in-depth studies of this form of language. In this paper we introduce CMU Multimodal Opinion Sentiment and Emotion Intensity (CMU-MOSEI), the largest dataset of sentiment analysis and emotion recognition to date. Using data from CMU-MOSEI and a novel multimodal fusion technique called the Dynamic Fusion Graph (DFG), we conduct experimentation to exploit how modalities interact with each other in human multimodal language. Unlike previously proposed fusion techniques, DFG is highly interpretable and achieves competative performance when compared to the previous state of the art. |
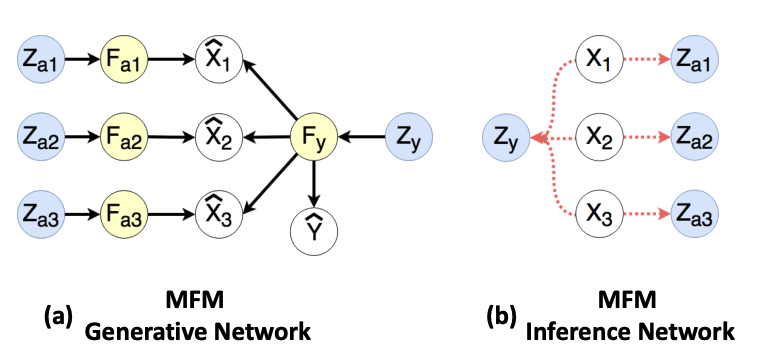
|
arXiv |
code |
abstract |
bibtex
Analyzing human multimodal language is an emerging area of research in NLP. Intrinsically this language is multimodal (heterogeneous), sequential and asynchronous; it consists of the language (words), visual (expressions) and acoustic (paralinguistic) modalities all in the form of asynchronous coordinated sequences. From a resource perspective, there is a genuine need for large scale datasets that allow for in-depth studies of this form of language. In this paper we introduce CMU Multimodal Opinion Sentiment and Emotion Intensity (CMU-MOSEI), the largest dataset of sentiment analysis and emotion recognition to date. Using data from CMU-MOSEI and a novel multimodal fusion technique called the Dynamic Fusion Graph (DFG), we conduct experimentation to exploit how modalities interact with each other in human multimodal language. Unlike previously proposed fusion techniques, DFG is highly interpretable and achieves competative performance when compared to the previous state of the art. |
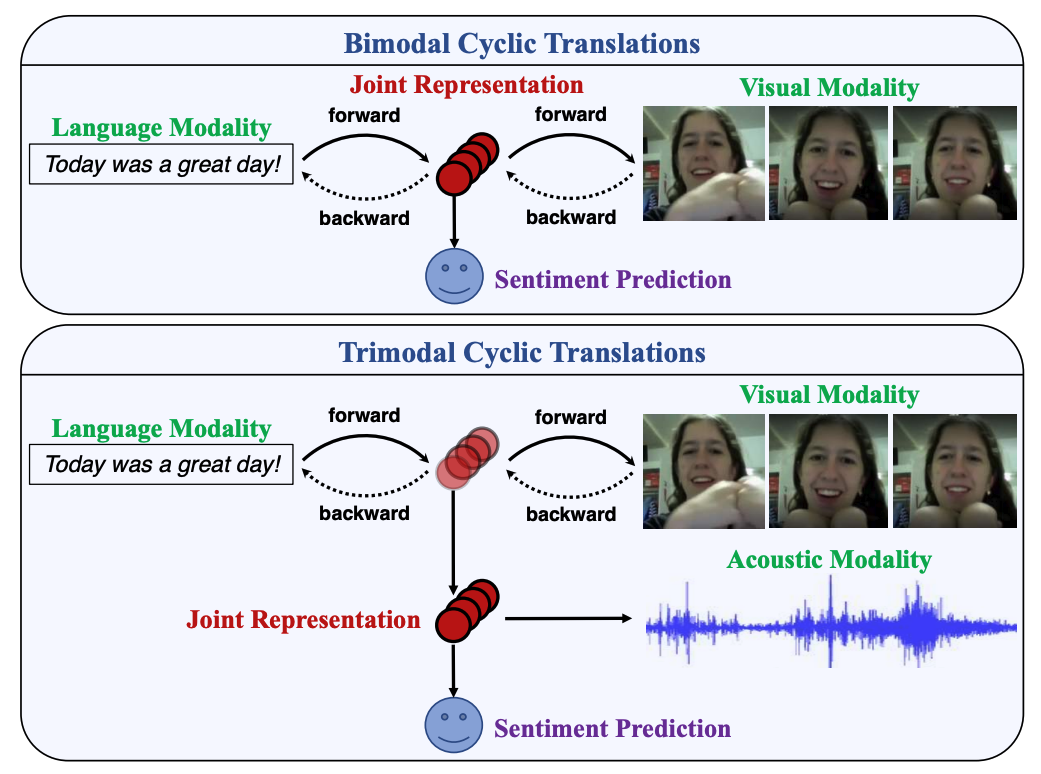
|
arXiv |
code |
abstract |
bibtex
Analyzing human multimodal language is an emerging area of research in NLP. Intrinsically this language is multimodal (heterogeneous), sequential and asynchronous; it consists of the language (words), visual (expressions) and acoustic (paralinguistic) modalities all in the form of asynchronous coordinated sequences. From a resource perspective, there is a genuine need for large scale datasets that allow for in-depth studies of this form of language. In this paper we introduce CMU Multimodal Opinion Sentiment and Emotion Intensity (CMU-MOSEI), the largest dataset of sentiment analysis and emotion recognition to date. Using data from CMU-MOSEI and a novel multimodal fusion technique called the Dynamic Fusion Graph (DFG), we conduct experimentation to exploit how modalities interact with each other in human multimodal language. Unlike previously proposed fusion techniques, DFG is highly interpretable and achieves competative performance when compared to the previous state of the art. |
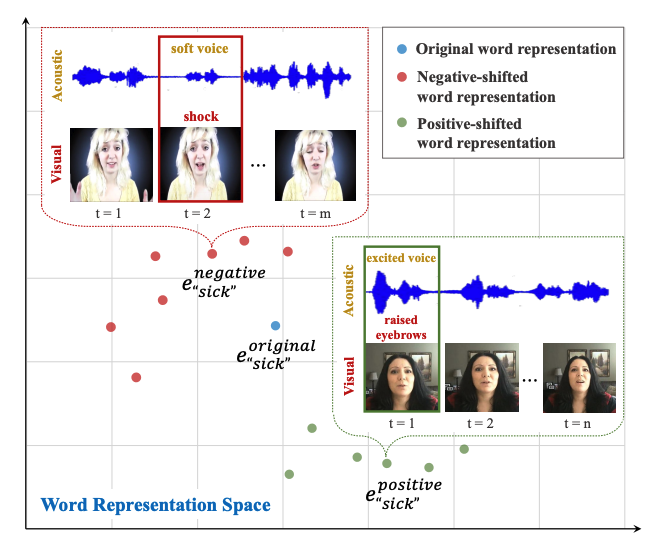
|
arXiv |
code |
abstract |
bibtex
Analyzing human multimodal language is an emerging area of research in NLP. Intrinsically this language is multimodal (heterogeneous), sequential and asynchronous; it consists of the language (words), visual (expressions) and acoustic (paralinguistic) modalities all in the form of asynchronous coordinated sequences. From a resource perspective, there is a genuine need for large scale datasets that allow for in-depth studies of this form of language. In this paper we introduce CMU Multimodal Opinion Sentiment and Emotion Intensity (CMU-MOSEI), the largest dataset of sentiment analysis and emotion recognition to date. Using data from CMU-MOSEI and a novel multimodal fusion technique called the Dynamic Fusion Graph (DFG), we conduct experimentation to exploit how modalities interact with each other in human multimodal language. Unlike previously proposed fusion techniques, DFG is highly interpretable and achieves competative performance when compared to the previous state of the art. |

|
arXiv |
code |
abstract |
bibtex
Analyzing human multimodal language is an emerging area of research in NLP. Intrinsically this language is multimodal (heterogeneous), sequential and asynchronous; it consists of the language (words), visual (expressions) and acoustic (paralinguistic) modalities all in the form of asynchronous coordinated sequences. From a resource perspective, there is a genuine need for large scale datasets that allow for in-depth studies of this form of language. In this paper we introduce CMU Multimodal Opinion Sentiment and Emotion Intensity (CMU-MOSEI), the largest dataset of sentiment analysis and emotion recognition to date. Using data from CMU-MOSEI and a novel multimodal fusion technique called the Dynamic Fusion Graph (DFG), we conduct experimentation to exploit how modalities interact with each other in human multimodal language. Unlike previously proposed fusion techniques, DFG is highly interpretable and achieves competative performance when compared to the previous state of the art. |
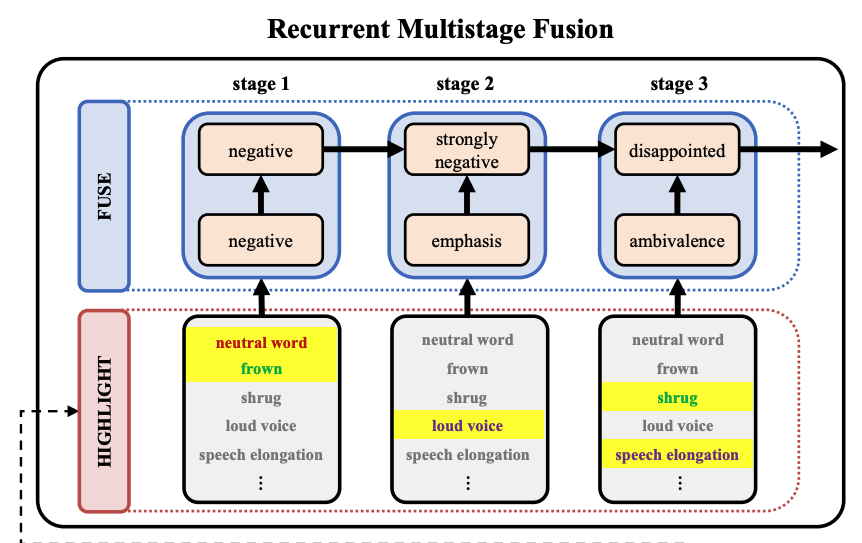
|
arXiv |
abstract |
bibtex
Analyzing human multimodal language is an emerging area of research in NLP. Intrinsically this language is multimodal (heterogeneous), sequential and asynchronous; it consists of the language (words), visual (expressions) and acoustic (paralinguistic) modalities all in the form of asynchronous coordinated sequences. From a resource perspective, there is a genuine need for large scale datasets that allow for in-depth studies of this form of language. In this paper we introduce CMU Multimodal Opinion Sentiment and Emotion Intensity (CMU-MOSEI), the largest dataset of sentiment analysis and emotion recognition to date. Using data from CMU-MOSEI and a novel multimodal fusion technique called the Dynamic Fusion Graph (DFG), we conduct experimentation to exploit how modalities interact with each other in human multimodal language. Unlike previously proposed fusion techniques, DFG is highly interpretable and achieves competative performance when compared to the previous state of the art. |
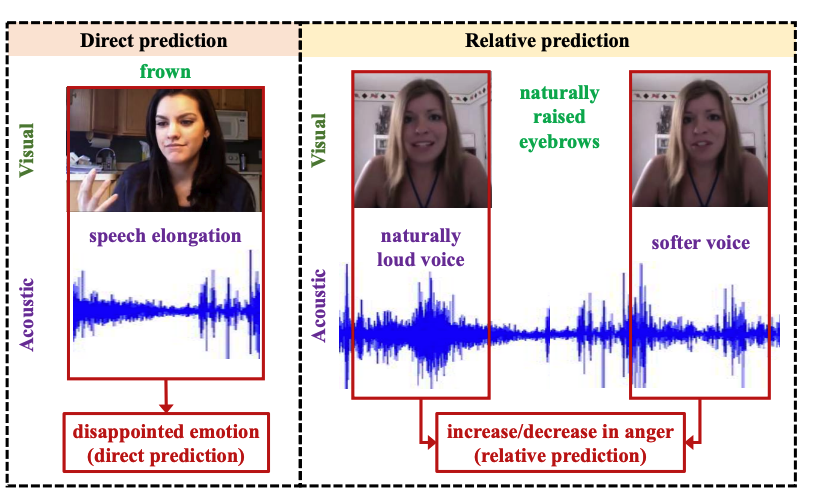
|
arXiv |
abstract |
bibtex
Analyzing human multimodal language is an emerging area of research in NLP. Intrinsically this language is multimodal (heterogeneous), sequential and asynchronous; it consists of the language (words), visual (expressions) and acoustic (paralinguistic) modalities all in the form of asynchronous coordinated sequences. From a resource perspective, there is a genuine need for large scale datasets that allow for in-depth studies of this form of language. In this paper we introduce CMU Multimodal Opinion Sentiment and Emotion Intensity (CMU-MOSEI), the largest dataset of sentiment analysis and emotion recognition to date. Using data from CMU-MOSEI and a novel multimodal fusion technique called the Dynamic Fusion Graph (DFG), we conduct experimentation to exploit how modalities interact with each other in human multimodal language. Unlike previously proposed fusion techniques, DFG is highly interpretable and achieves competative performance when compared to the previous state of the art. |

|
arXiv |
code |
abstract |
bibtex
Analyzing human multimodal language is an emerging area of research in NLP. Intrinsically this language is multimodal (heterogeneous), sequential and asynchronous; it consists of the language (words), visual (expressions) and acoustic (paralinguistic) modalities all in the form of asynchronous coordinated sequences. From a resource perspective, there is a genuine need for large scale datasets that allow for in-depth studies of this form of language. In this paper we introduce CMU Multimodal Opinion Sentiment and Emotion Intensity (CMU-MOSEI), the largest dataset of sentiment analysis and emotion recognition to date. Using data from CMU-MOSEI and a novel multimodal fusion technique called the Dynamic Fusion Graph (DFG), we conduct experimentation to exploit how modalities interact with each other in human multimodal language. Unlike previously proposed fusion techniques, DFG is highly interpretable and achieves competitive performance when compared to the previous state of the art. |
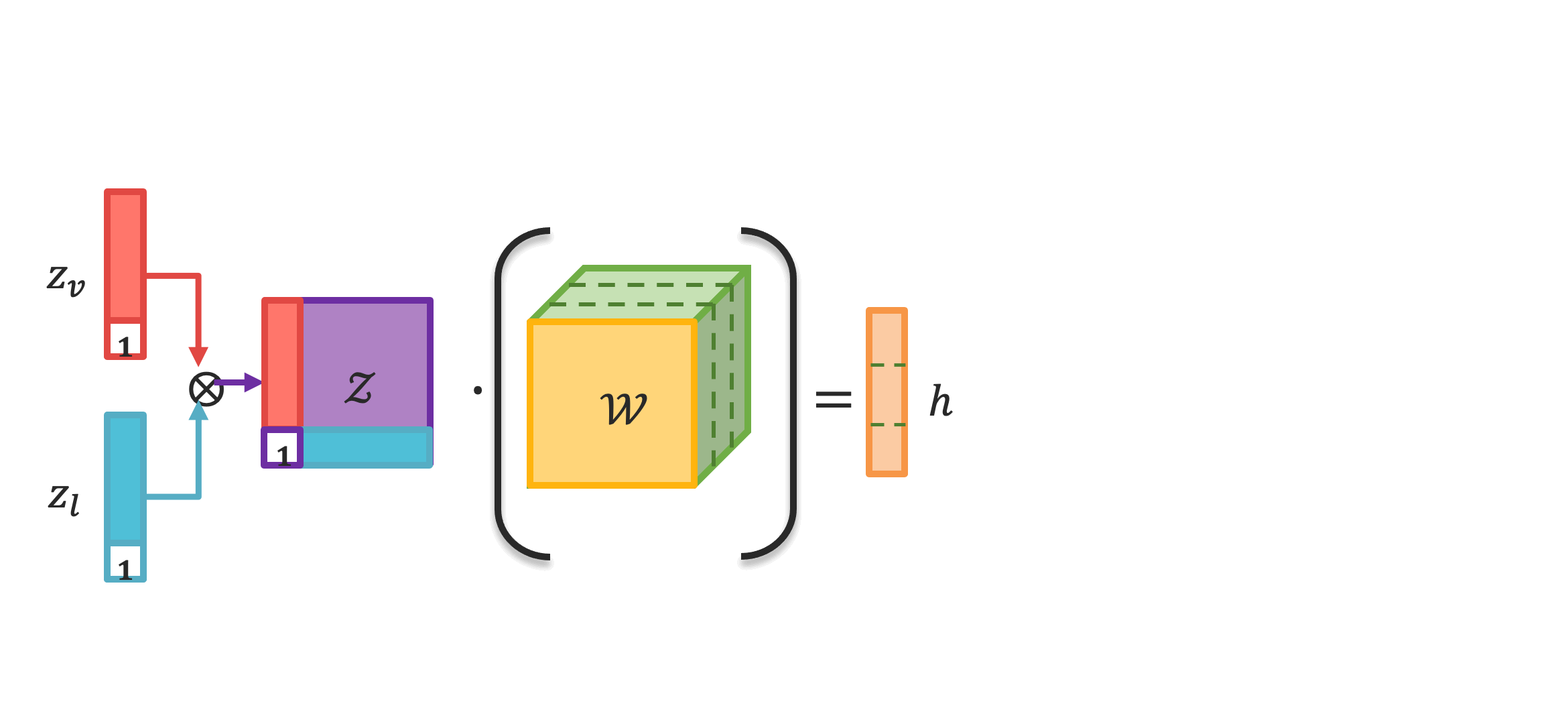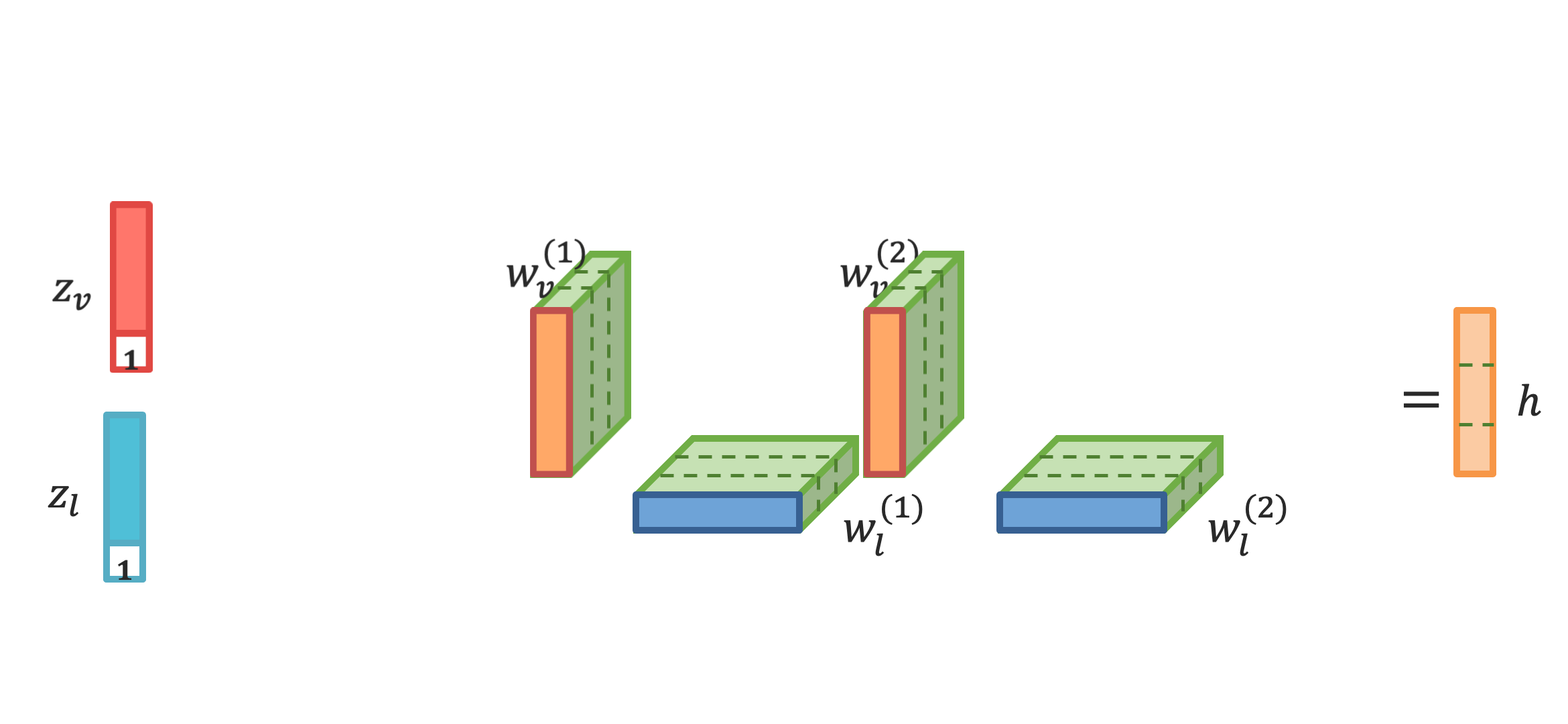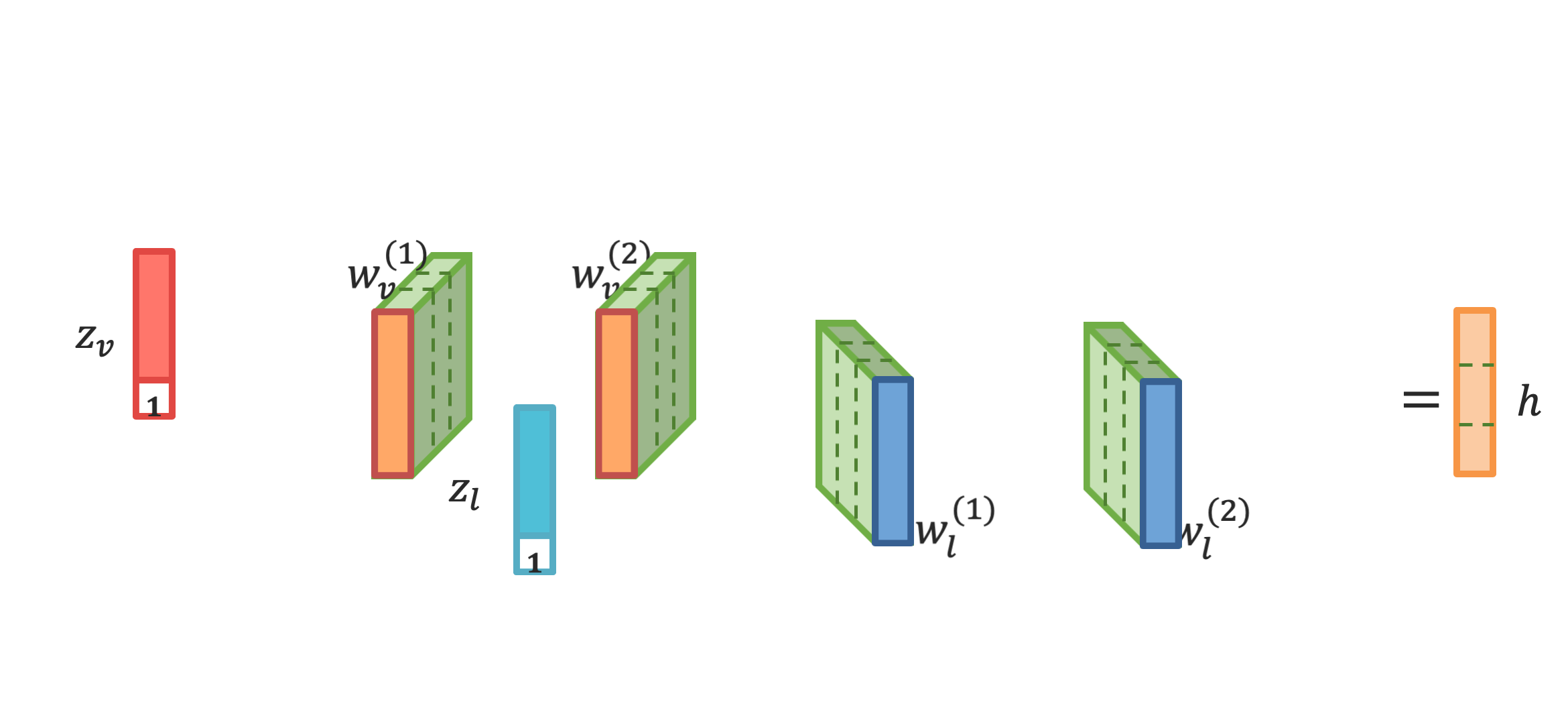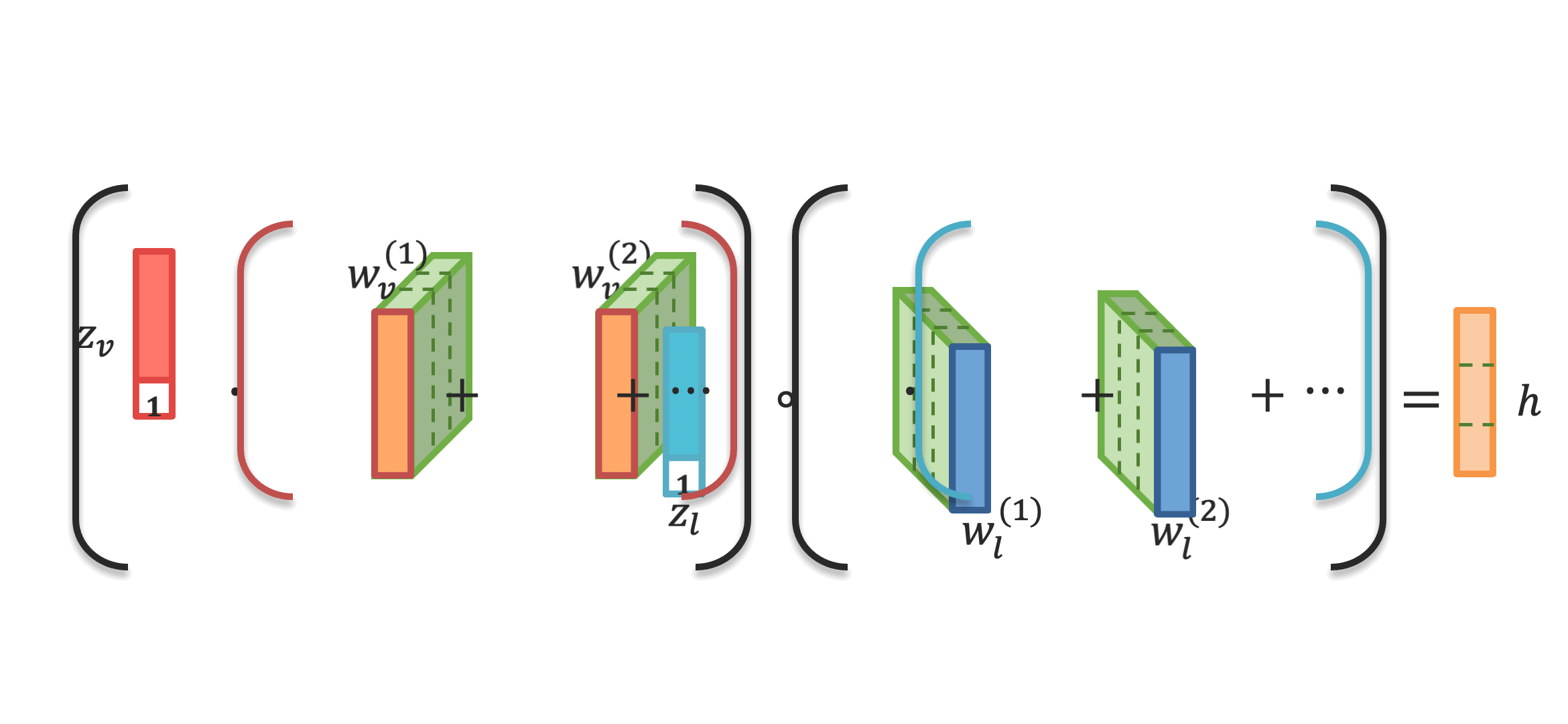
|
arXiv |
code |
abstract |
bibtex
Analyzing human multimodal language is an emerging area of research in NLP. Intrinsically this language is multimodal (heterogeneous), sequential and asynchronous; it consists of the language (words), visual (expressions) and acoustic (paralinguistic) modalities all in the form of asynchronous coordinated sequences. From a resource perspective, there is a genuine need for large scale datasets that allow for in-depth studies of this form of language. In this paper we introduce CMU Multimodal Opinion Sentiment and Emotion Intensity (CMU-MOSEI), the largest dataset of sentiment analysis and emotion recognition to date. Using data from CMU-MOSEI and a novel multimodal fusion technique called the Dynamic Fusion Graph (DFG), we conduct experimentation to exploit how modalities interact with each other in human multimodal language. Unlike previously proposed fusion techniques, DFG is highly interpretable and achieves competative performance when compared to the previous state of the art. |
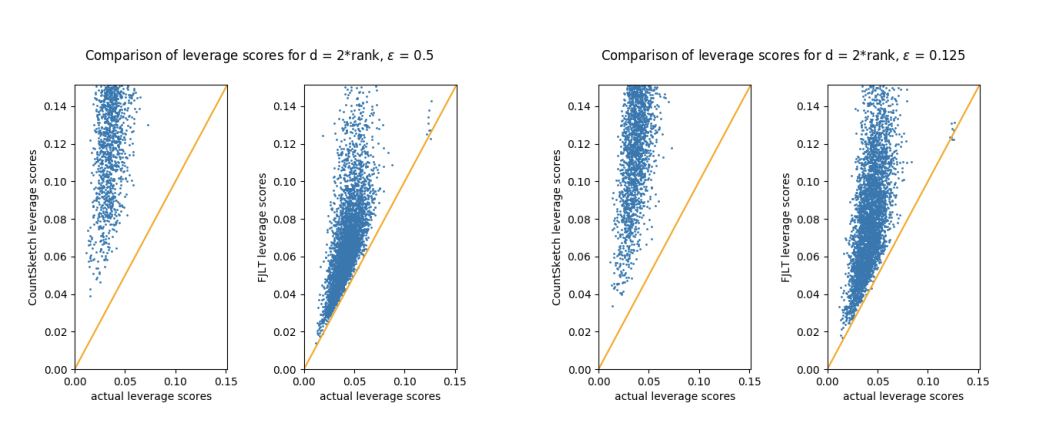
|
arXiv |
abstract |
bibtex
Analyzing human multimodal language is an emerging area of research in NLP. Intrinsically this language is multimodal (heterogeneous), sequential and asynchronous; it consists of the language (words), visual (expressions) and acoustic (paralinguistic) modalities all in the form of asynchronous coordinated sequences. From a resource perspective, there is a genuine need for large scale datasets that allow for in-depth studies of this form of language. In this paper we introduce CMU Multimodal Opinion Sentiment and Emotion Intensity (CMU-MOSEI), the largest dataset of sentiment analysis and emotion recognition to date. Using data from CMU-MOSEI and a novel multimodal fusion technique called the Dynamic Fusion Graph (DFG), we conduct experimentation to exploit how modalities interact with each other in human multimodal language. Unlike previously proposed fusion techniques, DFG is highly interpretable and achieves competative performance when compared to the previous state of the art. |
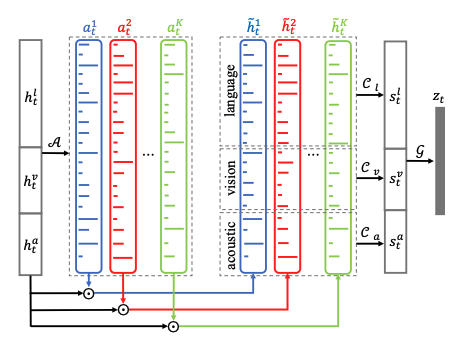
|
arXiv |
code |
abstract |
bibtex
Analyzing human multimodal language is an emerging area of research in NLP. Intrinsically this language is multimodal (heterogeneous), sequential and asynchronous; it consists of the language (words), visual (expressions) and acoustic (paralinguistic) modalities all in the form of asynchronous coordinated sequences. From a resource perspective, there is a genuine need for large scale datasets that allow for in-depth studies of this form of language. In this paper we introduce CMU Multimodal Opinion Sentiment and Emotion Intensity (CMU-MOSEI), the largest dataset of sentiment analysis and emotion recognition to date. Using data from CMU-MOSEI and a novel multimodal fusion technique called the Dynamic Fusion Graph (DFG), we conduct experimentation to exploit how modalities interact with each other in human multimodal language. Unlike previously proposed fusion techniques, DFG is highly interpretable and achieves competative performance when compared to the previous state of the art. |
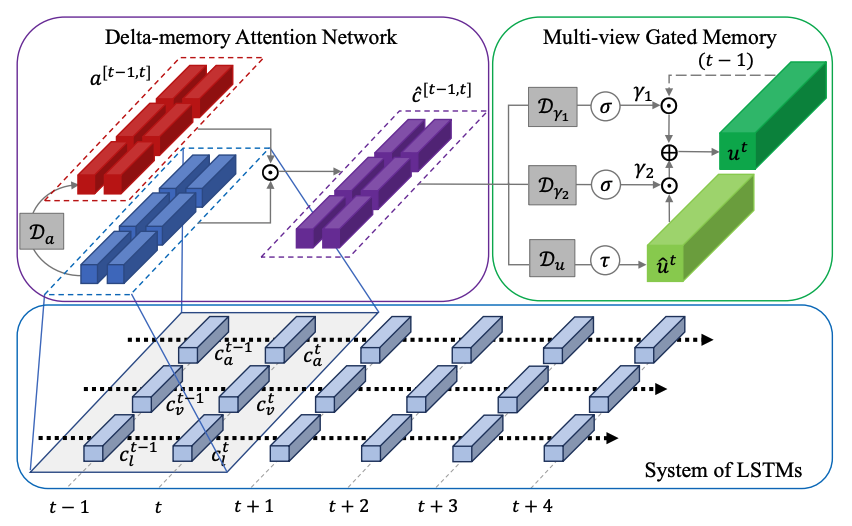
|
arXiv |
code |
abstract |
bibtex
Analyzing human multimodal language is an emerging area of research in NLP. Intrinsically this language is multimodal (heterogeneous), sequential and asynchronous; it consists of the language (words), visual (expressions) and acoustic (paralinguistic) modalities all in the form of asynchronous coordinated sequences. From a resource perspective, there is a genuine need for large scale datasets that allow for in-depth studies of this form of language. In this paper we introduce CMU Multimodal Opinion Sentiment and Emotion Intensity (CMU-MOSEI), the largest dataset of sentiment analysis and emotion recognition to date. Using data from CMU-MOSEI and a novel multimodal fusion technique called the Dynamic Fusion Graph (DFG), we conduct experimentation to exploit how modalities interact with each other in human multimodal language. Unlike previously proposed fusion techniques, DFG is highly interpretable and achieves competative performance when compared to the previous state of the art. |
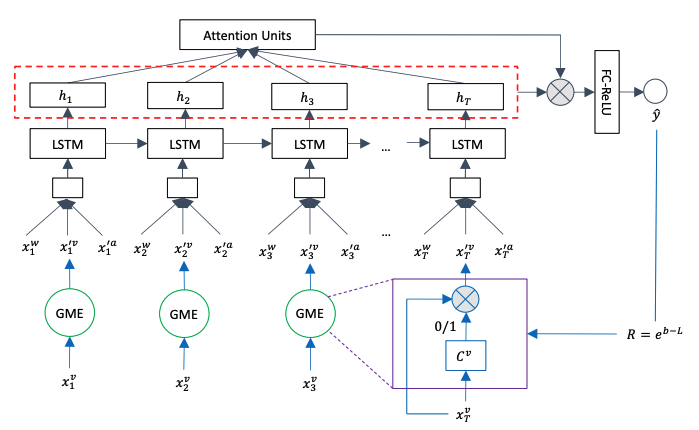
|
arXiv |
code |
abstract |
bibtex
With the increasing popularity of video sharing websites such as YouTube and Facebook, multimodal sentiment analysis has received increasing attention from the scientific community. Contrary to previous works in multimodal sentiment analysis which focus on holistic information in speech segments such as bag of words representations and average facial expression intensity, we propose a novel deep architecture for multimodal sentiment analysis that is able to perform modality fusion at the word level. In this paper, we propose the Gated Multimodal Embedding LSTM with Temporal Attention (GME-LSTM(A)) model that is composed of 2 modules. The Gated Multimodal Embedding allows us to alleviate the difficulties of fusion when there are noisy modalities. The LSTM with Temporal Attention can perform word level fusion at a finer fusion resolution between the input modalities and attends to the most important time steps. As a result, the GME-LSTM(A) is able to better model the multimodal structure of speech through time and perform better sentiment comprehension. We demonstrate the effectiveness of this approach on the publicly-available Multimodal Corpus of Sentiment Intensity and Subjectivity Analysis (CMU-MOSI) dataset by achieving state-of-the-art sentiment classification and regression results. Qualitative analysis on our model emphasizes the importance of the Temporal Attention Layer in sentiment prediction because the additional acoustic and visual modalities are noisy. We also demonstrate the effectiveness of the Gated Multimodal Embedding in selectively filtering these noisy modalities out. These results and analysis open new areas in the study of sentiment analysis in human communication and provide new models for multimodal fusion. |
Modified version of template from here |
Analyzing human multimodal language is an emerging area of research in NLP. Intrinsically this language is multimodal (heterogeneous), sequential and asynchronous; it consists of the language (words), visual (expressions) and acoustic (paralinguistic) modalities all in the form of asynchronous coordinated sequences. From a resource perspective, there is a genuine need for large scale datasets that allow for in-depth studies of this form of language. In this paper we introduce CMU Multimodal Opinion Sentiment and Emotion Intensity (CMU-MOSEI), the largest dataset of sentiment analysis and emotion recognition to date. Using data from CMU-MOSEI and a novel multimodal fusion technique called the Dynamic Fusion Graph (DFG), we conduct experimentation to exploit how modalities interact with each other in human multimodal language. Unlike previously proposed fusion techniques, DFG is highly interpretable and achieves competative performance when compared to the previous state of the art.