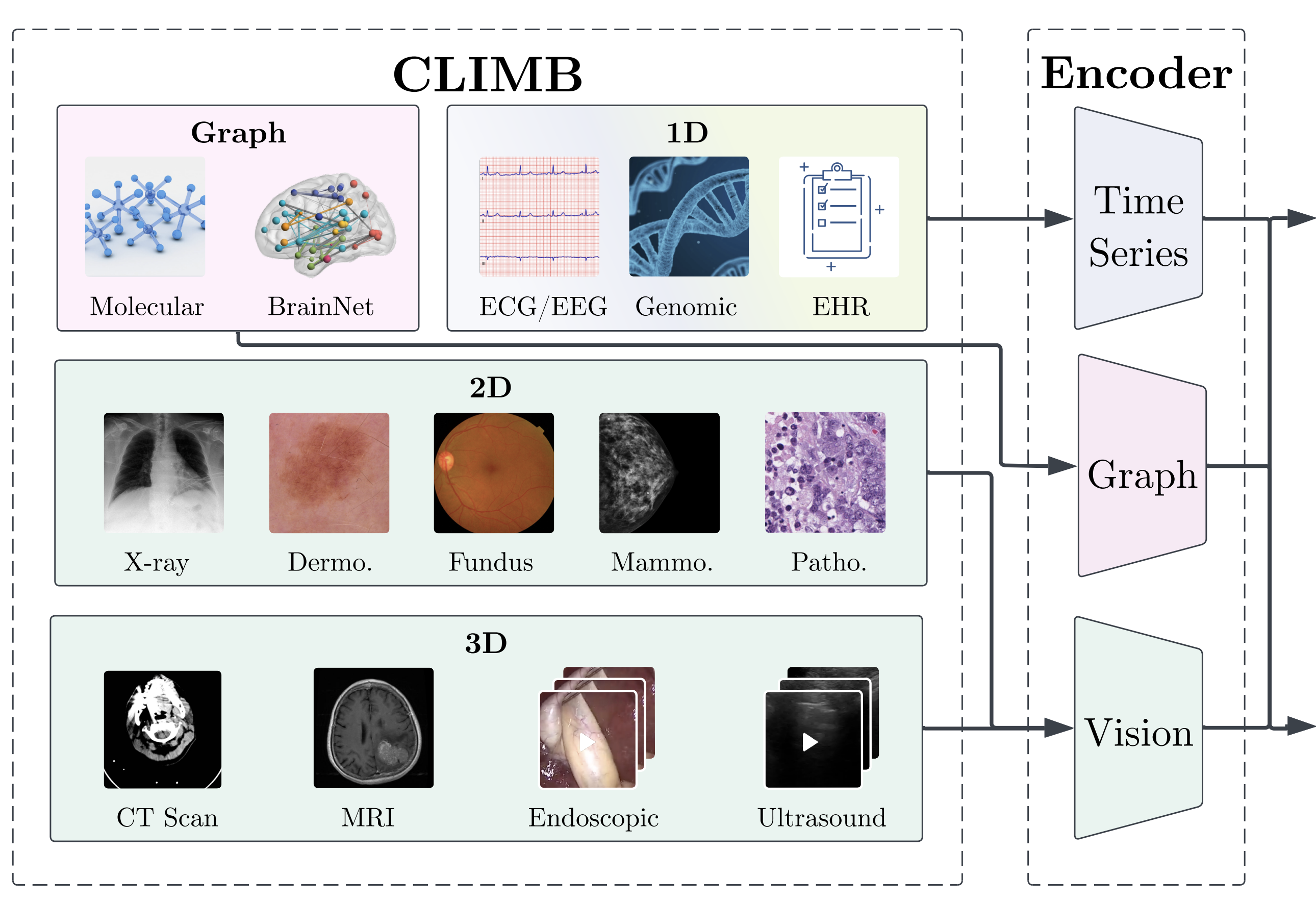
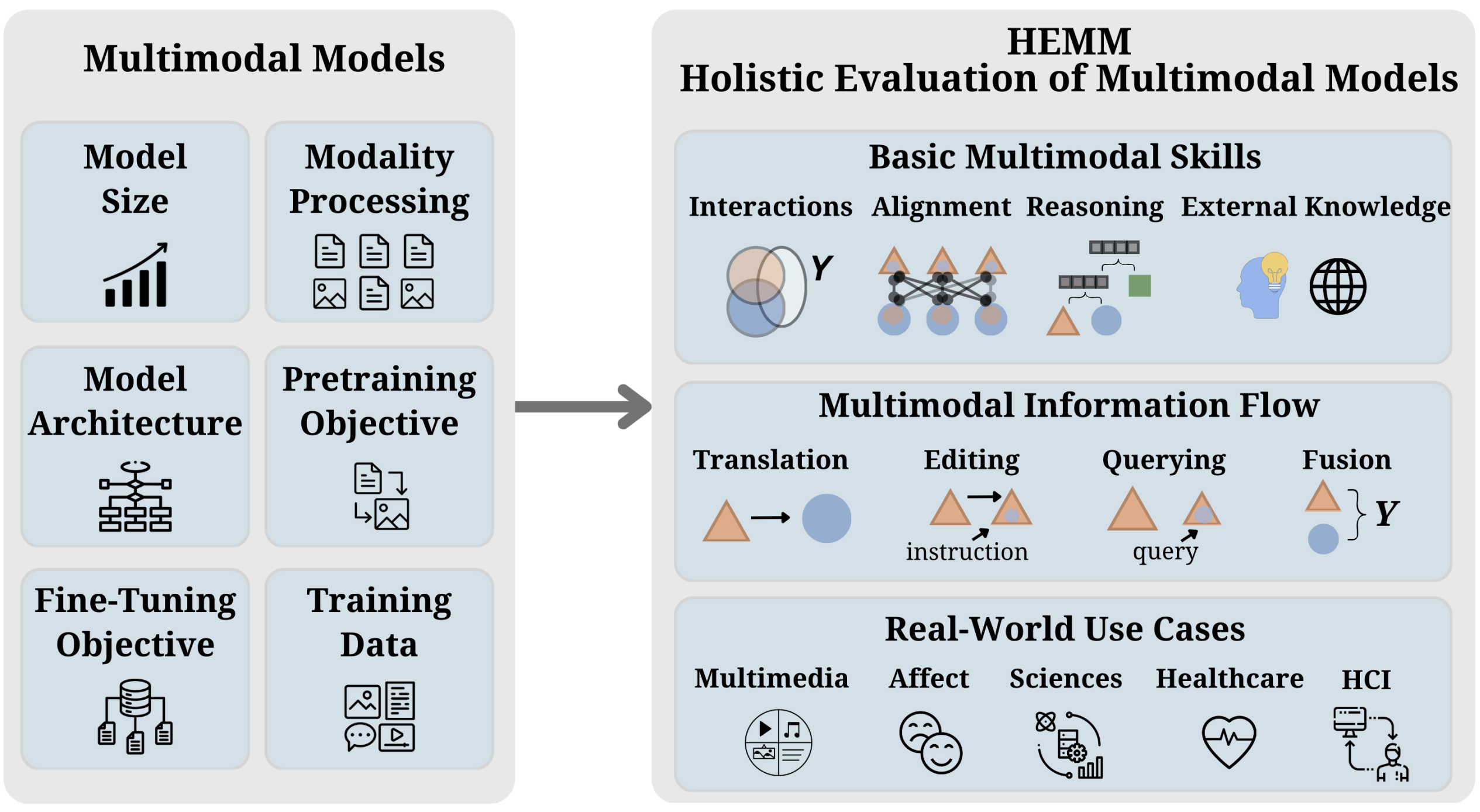
I am an Assistant Professor at the MIT Media Lab and MIT EECS, where I direct the Multisensory Intelligence research group. Our group develops the foundations of self-evolving multisensory AI to advance human capabilities and well-being.
Prospective students: I am hiring at all levels (post-docs, PhDs, masters, undergrads, and visitors). If you want to join MIT as a graduate student, please apply through the programs in Media Arts & Sciences, EECS,
or IDSS, and mention my name in your application.
I'm also happy to collaborate and answer questions about my research and MIT programs, I especially encourage students from underrepresented groups to reach out.
Our group develops the foundations of self-evolving multisensory AI to advance the human experience, through three thrusts:
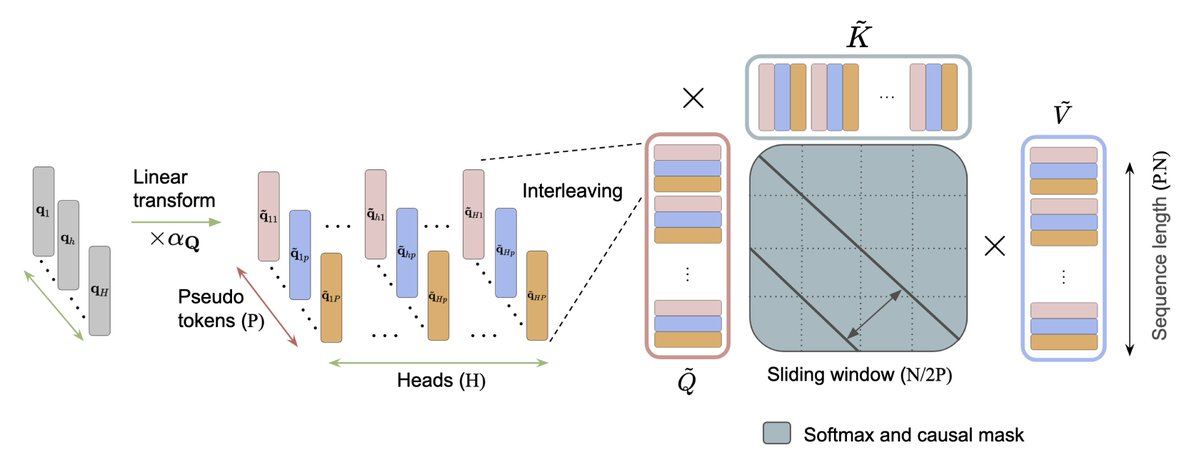
(1) Foundations of multisensory AI: The science and engineering of AI systems that can learn, reason, and interact with the world through integrating diverse sensory channels.
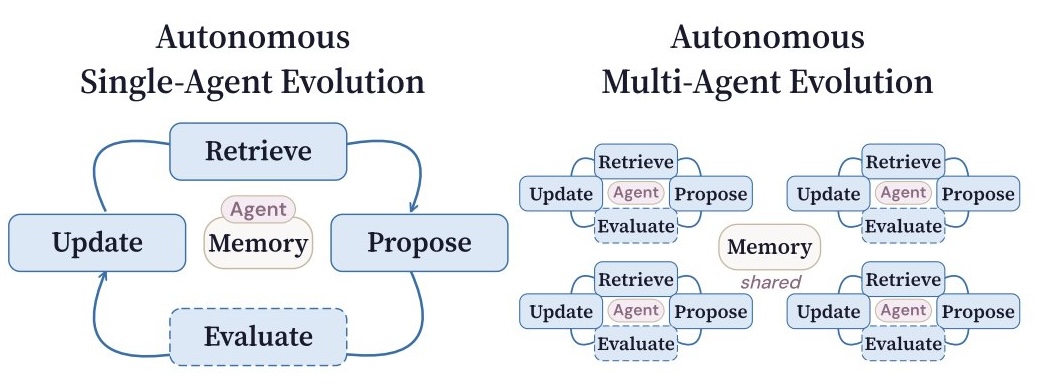
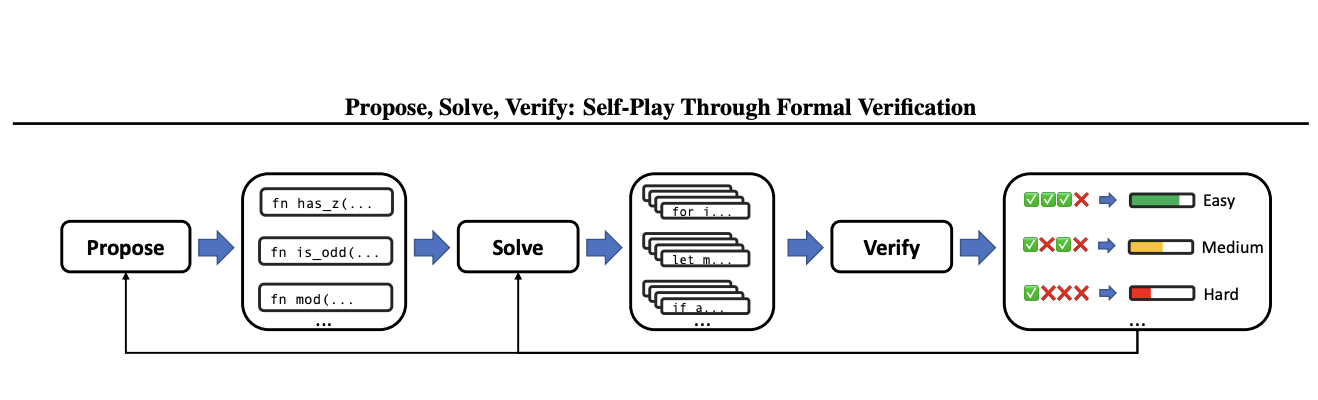
(2) Foundations of self-evolving AI: Developing AI systems that recursively learn, reason, and improve their own capabilities through continual interaction with data, environments, and users.
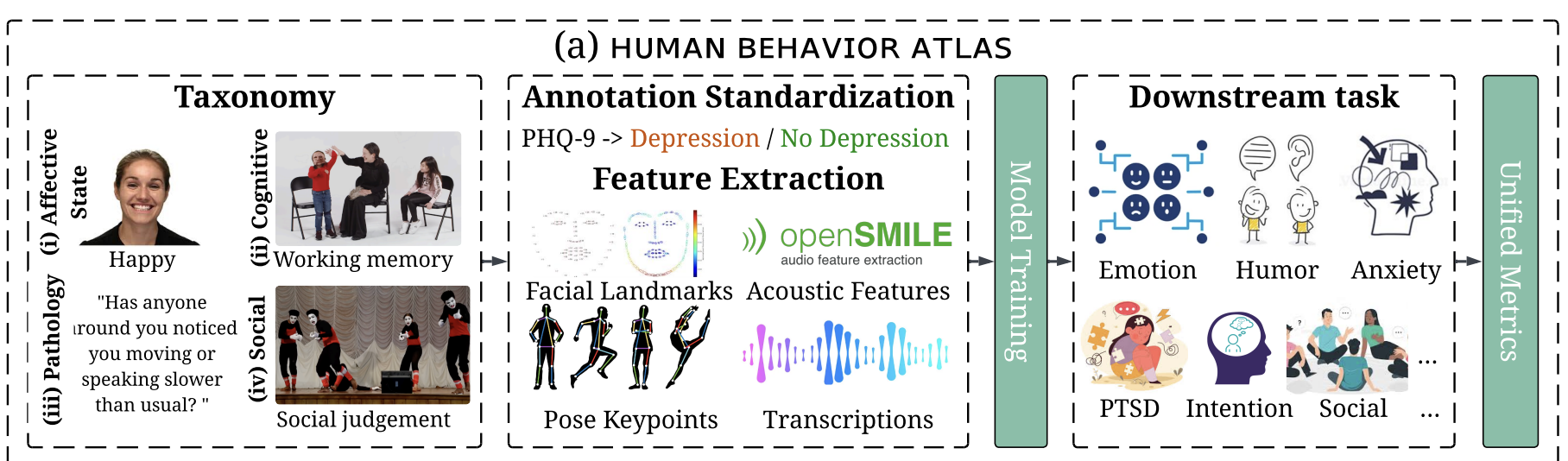
(3) Enhancing human experiences: Designing interactive AI technologies to augment human capabilities and improve overall well-being.
Lily Chen, now PhD student at Stanford Devin Murphy, now PhD student at University of Washington Haofei Yu, now PhD student at UIUC Rohan Pandey, now researcher at Open AI (best CMU senior thesis award) Yun Cheng, now PhD student at Princeton Rulin Shao, now PhD student at University of Washington Xiang Fan, now PhD student at the University of Washington (CRA outstanding undergrad researcher honorable mention) Jivat Neet, then research fellow at Microsoft Research, now PhD student at UC Berkeley Yiwei Lyu, now PhD student at the University of Michigan (CRA outstanding undergrad researcher honorable mention) Yuxin Xiao, now PhD student at MIT Peter Wu, now PhD student at UC Berkeley Dong Won Lee, now PhD student at MIT Terrance Liu, now PhD student at CMU Chengfeng Mao, now PhD student at MIT Ziyin Liu, then PhD student at the University of Tokyo, now research scientist at MIT